
V posledních pár letech se pojem “umělá inteligence” stal každodenní záležitostí. Pro mladší generace už je to běžná součást života, stejně jako mobily, zatímco pro starší generace je to často pořád velká neznámá. Začíná to ale vypadat, že v příštích pár letech budete úplně mimo, když nebudete umět tuhle věc používat. O co ale přesně jde? Je ChatGPT “inteligentní”? Je užitečnej? Je nebezpečnej? Měli bysme ho na něco používat? Trochu si celou tuhle záležitost přiblížíme.
V první řadě je tu otázka, co je vlastně “umělá inteligence” a jak je definovaná. Běžný zdroje nás poučí, že umělá inteligence označuje schopnost počítačovejch systémů vykonávat úkoly typický pro lidskou inteligenci, jako je učení, uvažování, řešení problémů, vnímání a rozhodování. Tudíž zjednodušeně je to něco, co neni člověk ani jiná živá bytost, ale dokáže to nějak napodobit lidskou inteligenci.
Jak ale uvidíme, tahle definice je trochu vágní a to, co se dneska prezentuje jako “umělá inteligence”, tuhle definici splňuje jen zlomkovitě. Budeme se tu zabejvat hlavně dneska už běžnejma a rozšířenejma chatbotama jako ChatGPT, ačkoliv aplikace těchhle modelů už jsou docela široký. Pro začátek se můžeme podívat na dva články, který trochu zchladí nadšení typu “hurá, máme umělou inteligenci!”:
» Uklidněte se, lidi, ChatGPT ve skutečnosti není umělá inteligence
» ChatGPT neni “skutečná umělá inteligence”. Počítačovej vědec vysvětluje proč
Jak už jsem párkrát uved, preferuju používat pojem “algoritmická inteligence” (zkratka AI zůstává stejná jako pro “artificial intelligence”), protože neni tak zavádějící – dává jasně najevo, že máme co do činění s algoritmama a ne s něčim, co se “vyrovná člověku”, což se to, co dneska máme k dispozici, rozhodně nevyrovná. První článek varuje před nebezpečím, že od současnejch AI můžou lidi očekávat schopnosti a vlastnosti, který ve skutečnosti nemaji, což může mít za následek víc problémů než užitku.

Ačkoliv ChatGPT údajně zvládne Turingův test (což se mi moc nezdá, protože rozeznat LLM od člověka se dá desítkama způsobů), kterej byl v 50. letech vymyšlenej jako test, jestli se stroj dokáže chovat inteligentně jako člověk, situace je trochu komplikovanější. Jak píše autor, Turingova představa byla, že když můžete se strojem konverzovat a nepoznáte, že je to stroj, musí bejt inteligentní jako člověk.
Turing ale netušil, jak se budou věci vyvíjet. Stalo se v podstatě to, že se v říši počítačů hodně vyvinula schopnost “konverzovat”, aniž by ruku v ruce s tim šly ostatní lidský vlastnosti spojovaný s inteligencí. Jak píše autor, ChatGPT je hodně dobrej v napodobování lidskejch jazykovejch vzorců, ale to dokáže i papoušek a ten moc inteligentní neni. A stejně jako ten papoušek, ChatGPT neví, co řiká.
Jak autor dál poznamenává, tak ačkoliv se u ChatGPT a dalších AI mluví o “učení”, neděje se to, že by ChatGPT šel a něco se naučil sám od sebe. “Naučí” se jen to, co mu programátor řekne, že se má naučit (a ukáže mu jak), což je dost omezená varianta “samo-učícího se stroje”.
Každej program dělá v první řadě to, co se mu řekne, že má dělat, takže se tu ani nedá mluvit o “učení” v pravym slova smyslu. Dnešní AI se v principu “neučí” o moc víc, než 30 let starý programy – jen dělá to, na co se naprogramuje – akorát dneska zvládá následovat podstatně komplexnější instrukce a generovat nesrovnatelně pokročilejší výstupy extrémně rychle.
Autor druhýho článku si pokládá otázku, jestli po 70 letech hledání máme konečně k dispozici “skutečnou” umělou inteligenci. Odpověď je podle něj, že ne, a podtrhuje to tim, že modely jako ChatGPT nazývá přesnějším termínem LLM, (large language model), neboli je to “velkej jazykovej model”.
Tady se dostáváme ke kořeni toho, s čim máme vlastně co do činění, když dneska “používáme AI”, tj. ve skutečnosti LLM. Je to počítačovej model jazyka, kterýmu jeho tvůrce nacpe do krku obrovský množství textu a učí ho s nima zacházet. Celá pointa je naprogramovat tuhle věc tak, aby dokázala “chápat” vstupní text, jako třeba vaše otázky, a generovat odpovědi, který dávaji smysl, a když bůh dá, tak byly i správný.
Kromě toho, že – jak si ukážeme pozdějc – bůh vždycky nedá, je důležitý si uvědomit, že tohle je zatraceně úzký zaměření a rámec “schopností” a k lidský inteligenci to má daleko. Na druhou stranu to dokáže spoustu zajímavejch věcí a úplně k zahození to neni. Na třetí stranu, jako každej nástroj, je to užitečný nebo nebezpečný podle toho, kdo to jak používá, a jak všichni víme, většina lidí jsou idioti a vládnou nám psychopati, takže možný důsledky si dokážete snadno domyslet.

Abysme se ale moc neupínali na myšlenku, že ChatGPT “neni AI” nebo neni “skutečná” AI, musíme se posunout k tomu, jak se s tim termínem zachází dneska, což znamená popsat si kategorie AI. Podle schopností se rozděluje na 3 kategorie:
- Úzká AI – navržená k plnění specifickejch úkolů v omezenym kontextu
- Obecná AI – dokáže vykonávat jakejkoli intelektuální úkol na úrovni člověka
- Superinteligentní AI – překračuje lidskou inteligenci ve všech oblastech
No a to, co se v době zavedení toho termínu hlavně myslelo “umělou inteligencí”, neboli tou, která by se vyrovnala člověku, je druhá skupina, která by se teoreticky vyvinula v tu třetí. A podstatnej poznatek pro nás je, že žádnou takovou AI nemáme.
Všechny formy toho, čemu se dneska řiká AI, který máme, včetně ChatGPT, spadaji do první kategorie. Neboli jsou navržený ke specifickýmu úkolu, v případě LLM k pokročilýmu zacházení s jazykem. Jak uvádí autor druhýho citovanýho článku, celá činnost ChatGPT se dá shrnout slovy “prompt completion”, což by se dalo přeložit jako “dokončení nápovědy”.
To je zhruba to, co LLM dělá. Vaše “otázka”, kterou položíte ChatGPT – a která ve skutečnosti nemusí mít formu otázky – se v angličtině nazývá “prompt” (nápověda, pobídnutí, výzva), a co LLM dělá, je to, že na to zareaguje na bázi předvídání, na což byl dlouho trénovanej na spoustě dat.
Když je to otázka, algoritmy se pokouší vyplivnout něco, co se dá považovat za smysluplnou odpověď. Když to neni jasná otázka, LLM se pokusí odhadnout, co chcete asi tak vědět o tom, co jste napsali, a odpovědět. To se dá často odvodit z kontextu, což je něco, v čem jsou LLM dobrý. Je jim celkem jedno, jestli napíšete “počasí dnes Ostrava” nebo “jaký bude dnes počasí v Ostravě”, protože z toho prvního si vyvodí, že je tak 99% pravděpodobnost, že to druhý je to, co chcete vědět, a odpoví na to.
Když napíšete totální neotázku, tak opět odhaduje, co by vás tak asi mohlo o tom zajímat. Napsal jsem do ChatGPT “brambory s jahodama” a on mi napsal, že to nejsou zrovna přísady, který by se běžně v kuchyni kombinovaly, ale že jestli mám chuť na dobrodružství, tam mi nabídne pár nápadů, co by se s nima dalo dělat, což udělal.
Takže to “dokončení nápovědy” je dost výstižnej popis. Ať plácnete cokoliv, LLM to nějak “dokončí”. Pokud se nesnažíte dělat si z těch chatbotů srandu a nějak je nachytat, tak vám obvykle řeknou to, co chcete vědět, protože na to jsou naprogramovaný – aby si co nejlíp vyvodili, co po nich chcete, a odpověděli vám způsobem, kterej napodobuje, co by vám odpověděl člověk, kterej pokud možno neni úplně blbej.

Schopnosti a omezení AI
Takže jsme si vyjasnili, že dnešní AI je “úzká AI”, neboli navržená na specifickej úkol, v případě LLM na práci s jazykem, což je ve srovnání s člověkem značně omezený. Proti člověku má ale několik výhod.
První, evidentní výhodou, jako u všeho počítačovýho, je rychlost. Počítače prostě zvládnou miliony operací, než my lidi se vůbec rozkoukáme. Těží mimo jiný i z toho, že je nezdržujou věci jako pochyby, vnitřní dialog, tréma, lenost nebo náhlá chuť na čokoládu.
Druhou výhodou, která je ale v podstatě jen důsledkem tý první, je, že maji k dispozici ohromný množství informací, řekněme celej Internet. To my máme víceméně taky, ale kvůli tomu rozdílu v rychlostech jsme schopni z toho zužitkovat jen malej fragment, zatímco AI dokáže pracovat s pro nás nepředstavitelným množstvím materiálu.
Jak je tohle užitečný v praxi, je evidentní. Je tu ale i spousta nevýhod/omezení algoritmický inteligence ve srovnání s lidma:
- nic ve skutečnosti “nechápe” a nedokáže samostatně “myslet”
- nedokáže poznat “pravdu” – jen vybírá “odpověď”, která “se zdá nejpravděpodobnější”
- nedokáže se “učit” kromě toho, co jí programátor řekne, aby se “učila” a jak
- chybí jí skutečná kreativita/originalita – jen rekombinuje existující vzorce
- může napsat kód podle instrukcí a naučenejch postupů, ale nevymyslí “novej”
- nedokáže vás vnímat jako specifickou osobu (protože nedokáže vnímat vůbec)
- nemá žádnej pojem o čase a tom, co se zrovna “děje”
- spotřebuje zhruba 10x víc elektřiny než obyčejný vyhledávání

Ačkoliv odpovědi AI můžou vypadat “inteligentně” a budit dojem, že ten chatbot “rozumí” tomu, o čem mluví, a “chápe”, co mu řikáte, je to jen iluze. Ve skutečnosti “nechápe” vůbec nic. Kromě toho naprosto “netuší”, jestli odpověď, kterou vám právě dal, je pravdivá nebo úplná kravina. A jakmile vám tu odpověď dá, tak i kdyby to byla sebevětší blbost, tak se za chvíli neozve a neřekne, “jé, počkej, sorry, to bylo blbě”. To může udělat, až když mu dáte další “prompt” a upozorníte ho na chyby. Do tý doby jako byste neexistovali ani vy, ani on. Mezi dvěma otázkama je v takový jako “hibernaci” a nehraje pro něj roli, jestli je v ní 10 vteřin nebo 10 let.
Je to prostě jen program, kterej vyhodnocuje data a něco na jejich základě generuje. Že to dělá rychle a někdy i dobře, je jiná věc.
Na druhou stranu, AI dokáže vytvářet lepší iluzi chápání než zombíci (natož politici) a domluva je s ní přece jen lepší. Za prvý neni agresivní a neuráží vás. Za druhý si poslechne všechny vaše otázky a argumenty a na všechny odpoví. Za třetí se vždycky snaží dát odpověď, která dává smysl. To je o dost víc, než můžete čekat od zombíků odchovanejch fanatickou televizní propagandou.
Zdánlivá “kreativita” AI pramení jen z toho, že lidi byli po tisíciletí kreativní a AI má z čeho čerpat – “tvoří” tak, že rekombinuje věci, který vytvořili lidi. Když budou lidi na všechno používat AI, hrozí, že kreativita vymizí a za nějakou dobu budou výsledky všeho prakticky identický.
Jelikož jazykový modely jsou dobrý na jazyky, můžete je použít na překládání. Do tohodle v podstatě zapadá i překladač DeepL. Trochu jsem ho používal pro minulej článek, kde jsem překládal hodně dlouhou konverzaci. Moc velkej dojem to na mě ale neudělalo. Rozhodně se to někdy hodí, když si lámete hlavu s tim, jak formulovat nějakou konkrétní myšlenku, ale problémů to má spoustu, nuance tomu unikaji, a občas to úplně změní význam věty.
Mezi jakž-takž překladem a dobrym překladem, kterej opravdu dává smysl, je obrovskej rozdíl. A AI umí jen to první. Nedokáže posoudit, jestli to dává smysl, nebo jestli je to to, co se ten originál opravdu pokoušel říct. Nad dobrym překladem musí člověk někdy opravdu dost přemejšlet v rámci širšího kontextu, jestli chce, aby byl přesnej a srozumitelnej, a AI tohle prostě nedokáže – jsou to pořád jen mechanický, i když složitý, algoritmy. Jako pomocník dobrý, ale bez lidský kontroly se tomu nedá věřit.

A pak tu máme i ten problém, že to spotřebuje hodně elektřiny (a dalších věcí), protože v pozadí probíhaji spousty kalkulací, obzvlášť při komplexních otázkách. A jelikož se dělaji pořád větší a náročnější modely, narůstá i spotřeba energie, což bude v příštích letech znát. (No ale třeba aspoň paraziti zjistěj, že ty jejich “zelený” elektrárny tu jejich AI neutáhnou, a bude se muset něco změnit.)
V rámci zkoumání schopností a omezení AI jsem dával AI spoustu otázek ohledně AI, což funguje docela dobře, protože AI obvykle ví celkem dost o tom, jak funguje AI. Takže jsem například položil otázku: “Co AI nedokáže, ve srovnání s lidma?” Zkrácená odpověď:
-
- I když AI dokáže ohromně pomoci s analýzou dat, automatizací úkolů a generováním kreativity, stále existují oblasti, kde jsou lidé nenahraditelní:
- Emoce a intuice – AI může rozpoznávat vzorce v lidském chování, ale skutečnou empatii, hluboké emoční porozumění a intuici, kterou lidé mají, nenahradí.
- Kreativita založená na osobní zkušenosti – AI umí generovat umění, hudbu nebo text, ale její tvorba postrádá osobní prožitek, kontext a lidské vzpomínky.
- Morální rozhodování – AI může pomoci s analýzou situací, ale etická rozhodnutí jsou hluboce lidská, protože vyžadují hodnoty, svědomí a uvědomění si důsledků.
- Fyzická obratnost – AI zvládne řídit auta nebo manipulovat s objekty, ale jemná motorika, přizpůsobivost a komplexní tělesná koordinace jsou zatím výsadou lidí.
- Spontaneita a improvizace – AI funguje na základě algoritmů, ale lidská schopnost jednat intuitivně, bez předchozího vzoru, je stále neporazitelná.
Na stejnou otázku v angličtině jsem dostal trochu jinej seznam, na němž byla důležitá položka “opravdu nezávislý uvažování“, což je dost klíčovej postřeh. Ve shrnutí pak bylo, že AI vždycky bude nástroj, kterej může doplňovat lidský schopnosti, ale nikdy je nenahradí.
Když dneska “používáte umělou inteligenci”, používáte stroje, který maji k plný definici inteligence hodně daleko – jsou to jen hodně komplexní algoritmy, který dokážou vysokou rychlostí zpracovávát ohromný množství dat a zacházet obratně s jazykem.

Užitečnost AI
Je AI užitečná? Rozhodně, ale jako se všim, musí se umět používat. Prvním předpokladem k lepšímu používání je vědět, co to je a co to neni a co to umí a co ne, což jsme si právě stručně načrtli.
Jaký problémy můžou vzniknout “špatným” používáním? A co je vůbec “špatný” používání AI? Dal bych to do dvou kategorií.
1. Pokud nechápete, že AI nic nechápe a má daleko ke skutečný inteligenci, natož neomylnosti, můžete její odpovědi brát nekriticky za bernou minci, ačkoliv jsou často nepřesný, zavádějící, až úplně mylný. AI neni něco, na co byste měli přehnaně spolýhat. Je to nástroj nebo pomocník; neni to něco, co je chytřejší než vy. (Teda pokud nejste Pekarová-Adamová. Nebo Černochová. Nebo Němcová. Nebo Nerudová. Nebo Jourová. Sakra, my těch krav máme.)
2. Pokud budete přehnaně spolýhat na pomoc AI, i kdyby byla efektivní, omezí to vaše vlastní učení a rozvoj. Když si zvyknete nic neřešit sami a nechat to na “někom jinym” (AI), časem nevyhnutelně dojde k tomu, že z vás bude neschopnej a nesamostatnej blb, kterej si sám s ničim neporadí a zapomněl, jak myslet. Čtenářům Antiviru už tohle asi moc nehrozí, ale rozhodně to akutně hrozí mladejm generacím a už se to děje teď.
AI je dobrá pomůcka pro ty, co si poradí i bez ní, ale nebezpečnej nástroj pro toho, kdo si bez něj neporadí. Neboli to patří mezi věci, o kterejch se řiká, že je to dobrej sluha, ale zlej pán. Když se ptáte na věci, kterejm rozumíte, dokážete celkem dobře posoudit správnost odpovědi; když o tématu nic nevíte, může vám AI nakukat cokoliv a nepoznáte, jestli je to naprosto správně nebo jen halucinace.
Nejzákladnější použití AI je jako náhrada vyhledávače. Místo abyste psali do něj a pak se proklikávali hromadou odkazů a doufali, že na jednom najdete to, co potřebujete, můžete dát dotaz AI a dostanete odpověď rovnou. Jestli to bude ta odpověď, jakou jste potřebovali, bude záležet na spoustě věcí – na tématu, obecný dostupnosti daný odpovědi na Internetu, ale taky na formulaci vašeho dotazu.
Tenhle postup je dobrej na otázky, na který existuje jasná správná odpověď. Tu pak dostanete snadno a rychle a ušetří vám to čas s tim proklikáváním odkazů. Už to tak dobře nebude fungovat na jakýkoliv kontroverzní témata – politika, zdraví atd. – takže tam to tak velkej smysl nemá. AI vám dá jako odpověď zhruba to, co byste našli mezi prvníma výsledkama na Goolagu, neboli propagandu. Odpověď dostanete vždycky, ale s pravdivostí je to podobný jako třeba na Wikiparodii. Dívejte se na AI jako na něco, co používá Goolag a studovalo z Wikiparodie, a podle toho odpovídá, protože tak to v podstatě je.
Je to ale dobrý na technický záležitosti, otázky, jak něco opravit, otázky ohledně Windows a programů, který používáte, geografický data, fakta o zvířatech a prostě věci, u kterejch neni žádná horká debata o tom, jestli je správná odpověď to nebo tamto. Počet nohou grizzlyho je jasnej. Kde leží Zimbabwe a kolik má obyvatel neni kontroverzní. Jak nastavit emailovej program, když znáte jeho verzi, by taky nemělo produkovat nějak extra nesprávný odpovědi.
A jelikož jsme ve světě výpočetní techniky, AI dokáže pomoct i s programováním a některý modely se na to specificky zaměřujou. AI vám pomůže konvertovat kód v pythonu do php nebo objasní, proč nějakej kód, kterej testujete, nedává výsledky, který čekáte – a třeba i jak to opravit. Samozřejmě to má omezení, ale v týhle oblasti to dokáže bejt užitečný.
Dneska dokáže AI celkem parádně generovat obrázky podle instrukcí (k tomu se vrátíme víc), generovat audio s hlasem konkrétního člověka (musí mít k dispozici jeho hlas) a textem, kterej mu zadáte, a do velký míry generovat i video, i když tam kvalita ještě trochu zaostává.

Přehled různejch AI
Kde si teda můžete “popovídat” s nějakym tim chatbotem a něco užitečnýho zjistit? A je jenom ChatGPT, nebo jich je víc? A kolik? To poslední vám řeknu přesně: je jich zatraceně hodně. Prostě se s tim roztrh pytel a jsou jich desítky, a když vezmeme v úvahu všechny verze a variace, tak stovky, a z toho můžete celkem slušný množství použít zadarmo a bez registrace.
Placený verze toho nabízeji víc a máte k dispozici přístup k lepším modelům a nástroje, který zadarmo nemáte, ale je to spíš pro pokročilý, profesionální používání. Samozřejmě nejsem blbej, abych platil za používání AI, takže o placenejch možnostech se bavit nebudeme.
Jiná otázka je, jestli si založit účet, protože i to někdy poskytuje výhody, nebo spíš odstraňuje nějaký omezení. Omezení bejvaji v tom, kolik otázek můžete dát za den (nebo jinej časovej úsek), kolik můžete vygenerovat obrázků, jak hodně můžete využívat nějakou lepší funkci jako komplexnější odpovědi, atd.
To už je na každym, co od toho chce. Pokud chcete vědět, jakej je rozdíl mezi používáním konkrétní AI bez registrace a s registrací, nejjednodušší je zeptat se přímo tý AI, nicméně specifikujte tu platformu, ať ví, že nemluvíte o registraci někde jinde. Pro běžný základní používání ale neni nutný se registrovat.
Na druhou stranu, bez registrace vás to často každou chvíli otravuje s vyskakujícíma oknama, který vám řikaji, že se máte přihlásit, abyste měli víc možností, a toho se registrací zbavíte. Registrace vám obvykle dá přístup k vašim předešlejm konverzacím, možnost upravit víc nastavení, a často zvýší limity, kolik čeho můžete dělat (jako počet zpráv na den).
V rámci experimentů jsem se zaregistroval asi na 10 místech a nenarazil jsem na žádnej problém, jako že by mě to otravovalo mailama nebo tak. Doporučoval bych vyzkoušet si pár platforem a až si vyberete, která se vám líbí, tak se tam zaregistrovat přes mail.
Projdeme si pár modelů, který jsem vyzkoušel.

ChatGPT
Neni ChatGPT jako ChatGPT. Jednak jsou v oběhu různý verze a jednak, jak jsem zjistil, různý platformy ten model používaji s různým nastavením a omezeníma, takže i když dvě platformy používaji ChatGPT 3.5, výsledky nebudou stejný.
V tuhle chvíli (což se ale rychle mění) se volně dostupnej ChatGPT posouvá od verze 3.5 k verzi 4, která má několik variant. Ta je momentálně nejnovější, lepší a ne všude dostupná zadarmo (velmi brzo určitě bude). K tomuhle botovi se dá dostat na různejch místech.
chatgpt.com je jedna možnost, kterou jsem ale moc netestoval. Podařilo se mi tam dát pár otázek bez registrace, ale vyskakuje tam žádost o registraci – tu můžete odkliknout a pokračovat, aspoň nějakou dobu, ale bude vás to dokola otravovat. Tohle je běžný na mnoha platformách.
Bez registrace je to hodně limitovaný. S bezplatnou registrací by tam měl bejt neomezenej přístup k základním funkcím, ale pořád s nějakejma limitama na počet otázek a podobně. (Teď mi to například píše 10 otázek za 5 hodin, ale tyhle limity se mění skoro denně.)
Jako první jsem zkoušel talkai.info. To bych moc nedoporučoval, protože mi to připadá nějaký natvrdlý. Obvykle jsou jeho odpovědi v lepším případě ne moc užitečný a v horším případě úplný blbosti. Dává mi odpovědi skoro typu “tohle si určitě můžeš najít někde na Internetu” (Vážně? Nejsi ty spíš chobot než chatbot?) a některý odpovědi jsou tak evidentně špatně, že člověk žasne, jak suverénně mu nějaká “inteligence” může říct takovou kravinu.
Kromě toho, zrovna teď jsem se ho kontrolně zeptal, kolik je ve vesmíru brambor a on mi řek, že žádný. Debil. Na doplňující otázku “Země neni ve vesmíru?” odpověděl “Ne, Země je planeta, která se nachází ve vesmíru.”, což nedává smysl. Doplnil, že “Vesmír zahrnuje všechny planety”, čimž vyvrátil pravdivost svojí první odpovědi. No prostě blb.
Navíc má taky ve zvyku pořád vám přes celou obrazovku nabízet “Try TalkAI Premium”, takže musíte furt odklikávat, ať s tim jde do háje. Takže to za to nestojí. Tohle jsou sice moje subjektivní postřehy, ale jedno je jistý: existujou lepší platformy.
Na čistý, pohodový používání ChatGPT bez zbytečnýho otravování bych doporučil tuhle. Ještě nedávno tam byla verze 3.5 a teď je tam “4o Mini”, což je nějaká menší verze čtyřky, jestli jste si to náhodou z toho názvu neodvodili sami. Tady byly odpovědi takový celkem normálně OK, i když nijak extenzivně jsem to netestoval.

Copilot
Copilot je AI Microsoftu, což je samozřejmě špatný, jenže na AI se prakticky podílí samý zazobaný pochybný korporace (Goolag, Meta, Amazon), takže si moc nevyberete. Tohle aspoň můžete používat zadarmo a bez registrace a funguje to relativně v pohodě.
Je to taky navíc specificky zaměřený na produkty Microsoftu, takže by vám to mělo umět dobře poradit s Windows, Office atd. Dá se ale použít všeobecně. Ve skutečnosti je to GPT4, dotrénovaný Microsoftem se specializací pro jejich potřeby. V poslední době se mu taky řiká “Copilot 365”, podle produktů MS.
Jen pro objasnění – existuje ještě Copilot na Githubu, kterej se specializuje na kódování/programování. Ačkoliv oba souvisí s Microsoftem (ten skoupil Github), je mezi nima rozdíl a ten Githubovej vyžaduje registraci. Nabízí ale několik modelů, včetně několika variant GPT4 a kvalitního modelu Claude 3.5 Sonnet. Koho zajímá víc technický využití AI v oblasti programování, může to okouknout.
Perplexity
Tuhle Platformu jsem si zatim oblíbil nejvíc. Paradoxně v době mejch prvních testů používala převážnětaky GPT-3.5, ale evidentně je to jinak vyladěný, protože mi tam ty odpovědi vždycky připadaji nějak lepší a jsou rozhodně jiný, než když tu samou otázku dám třiapůlce jinde. V současný době byl ChatGPT nahrazenej modelem Sonar, kterej je přímo od Perplexity.
Perplexity AI má k dispozici pro platící uživatele 8 LLM. Můžete si buď vybrat, nebo nechat platformu, ať vybere model nejvhodnější pro vaši otázku. Zeptal jsem se, co z toho se používá bez placení.
Zjistil jsem, že je to převážně jejich optimalizovaná verze GPT-3.5 připojená k Internetu, ale částečně se využívá i jejich vlastní model R1 1776 (kterej byl jednim z prvních necenzurovanejch modelů). S nějakym limitem několika otázek na hodinu se využívá i GPT-4, ačkoliv normálně je rezervovanej pro platící. Takže je to nějaká kombinace aspoň tří modelů s tim, že 3.5 je líp vyladěnej tou platformou. (Jak už jsem řek, GPT teď nahradili Sonarem.)
S timhle jsem experimentoval trochu víc a byl jsem dost spokojenej s radama ohledně nějakejch dost složitejch technickejch záležitostí a snad se mi nestalo, že by byla nějaká odpověď fakt blbá. Chyby se sem tam najdou, ale to je normál všude. Perplexity se specificky zaměřuje na výzkum a odpovědi založený na faktech – na rozdíl od populárních modelů víc zaměřenejch na konverzaci.
Perplexity jsem objevil tak, že jsem se zeptal Copilota na nějaký dobrý AI na technický otázky a řešení problémů, a ten mi řek (kromě jinejch tipů), že Perplexity je “známá svojí přesností v odpovídání na komplexní otázky v mnoha oblastech”.
Tim se dostáváme k faktu, že většinu AI nástrojů jsem našel tak, že jsem se nějaký AI zeptal, co je dobrý na to a to. Teď se většinou ptám Plexie, protože ty odpovědi maji hlavu a patu.

Grok
Groka znáte z minulýho článku a musim říct, že mě docela zaujal. Je nastavenej na delší a komplexnější odpovědi (což bylo užitečný v tý zmíněný konverzaci v článku) a takovej obecně příjemnej styl. Má víc “osobnosti” než ostatní. Navíc když na něj začnu mluvit svym “antivirovym” stylem, tak začne mluvit taky tak, což je docela cool.
Má nějaký omezení – momentálně 10 otázek za 2 hodiny (což by mělo bejt naprosto dostačující), ale umí i generovat a editovat obrázky, i když taky s omezením počtu na den. Registrace vám umožní dělat pár věcí, který bez ní nemůžete (jako upravovat nějaký nastavení), ale ty základní limity to nezvedne.
Registraci bych ale doporučoval kvůli přístupu k historii a nastavení. Pak si mimo jiné můžete nastavit například aby byly odpovědi stručný, kdyby vám nevyhovoval Grokův detailní styl, nebo mu dát vlastní instrukce, jak má obecně odpovídat. K týhle důležitý funkci se ještě dostaneme pozdějc.
U Groka můžete taky použít DeepSearch a DeeperSearch, abyste získali mnohem komplexnější analýzu. Trvá to pak několik minut, ale Grok prozkoumá mnohem víc aktuálních zdrojů na Internetu, pořádně to všechno analyzuje a dá vám propracovanější odpověď, víc zdrojů atd. Pozdějc si ukážeme nějakej příklad. (Podobnou funkci “Research” má i Perplexity.)
Na obrázku taky vidíte funkci “Think”. Ta “zapne extra logický obvody” a Grok si odpověď promyslí víc systematicky a prověřuje vlastní závěry. Je to zaměřený na myšlení, kalkulace a teoretickou analýzu, s větším důrazem na přesnost než na rychlost. Všechno je pak krok za krokem vysvětlený.
Claude AI
Claude AI je všeobecně považovaná za kvalitní volbu, s několika modelama jako Haiku, Sonnet, nebo Opus. Bezplatnej přístup je ale dost omezenej a obvykle jen ke starším modelům. Na jejich webu mi to momentálně píše, že nový uživatele nepřijímaji. Různý platformy vám ale ke starším modelům přístup daji.
Haiku je zaměřenej na rychlost, Sonnet je všeobecně schopnej a vyváženej a Opus je zaměřenej na hodně komplexní témata a odpovědi. Modely Claude se taky oproti konkurenci víc snaží držet toho, co vědí jistě, a maji větší tendenci přiznat, že něco neví, zatimco jiný modely si v takovejch případech něco vymyslí. Vzhledem k menší dostupnosti jsem neměl možnost to moc otestovat.
DeepSeek
DeepSeek je čínská AI, která se prej ve všech ohledech vyrovná “západním” modelům, ale – pozor – je o 90-95% levnější, což je sakra rozdíl. Číňani teda klasicky ukazujou, že všechno se dá dělat mnohem levnějc a přitom pořád dobře. Na platformě openrouter.ai můžete zkusit DeepSeek-R1 nebo DeepSeek V3. Při pár testech jsem na nich nenašel žádný závažný problémy.
Jedinej rozdíl byl, že ty odpovědi z nich lezou o dost pomalejc než z většiny ostatních. To zřejmě souvisí s tim, že jsou o hodně levnější a jede to na míň kvalitním hardwaru. Odpověď dostanete dobrou, ale trvá to dýl.
OpenRouter je platforma, kde si můžete vybrat z desítek různejch LLM modelů ke konverzaci. Napište si do vyhledávání “free” a uvidíte ty, který jsou zadarmo. Vyžaduje to ale registraci přes email. Podobná platforma je hix.ai, ale tam je to ještě trochu omezenější. Další je ten už zmiňovanej hotbot, a ten funguje i bez registrace.
Llama
Llama jsou modely od Meta neboli od Fujsbukářů. Přes odpor k Meta jsem nakonec zkusil i jeden z nich. Meta Llama 4 Maverick mě zaujal tim, že je zatraceně rychlej. I na komplexní otázky na celou stránku mi vyplivne odpověď za 1 vteřinu, a přitom to má hlavu a patu, chápe moje otázky správně, a delší konverzaci na komplexní téma zvládnul dobře. Pokud by vám šlo o rychlost, stojí za vyzkoušení.
Kromě toho ale Llama 4 Maverick i Llama 4 Scout maji ohromný kontextový okna, takže jsou schopný v “paměti” udržet hodně dlouhou konverzaci, včetně extra souborů jako pdf, a neztratit se v tom. Běžný kontextový okna jsou dneska 128 000 tokenů a Maverick má milión a Scout deset mega. A jsou zadarmo.
Tohle je teda několik běžnejch modelů, který můžete na různejch místech otestovat. Všechny zvládaji češtinu (koneckonců, jsou to jazykový modely), ale samozřejmě v angličtině fungujou líp, protože to je obvykle jejich výchozí jazyk, byly v něm trénovaný a maji v něm k dispozici mnohem víc materiálu.

Necenzurovaná AI
Jednou jsem se zeptal Perplexity, jaký AI jsou nejmíň cenzurovaný. Součástí všech modelů jsou totiž různý restrikce – od těch pochopitelnejch (aby vám nepředhazovali něco násilnýho, kriminálního, urážlivýho, pornografickýho a podobně) až po politickou korektnost a prachobyčejnou cenzuru. Ty nejběžnější AI jsou takhle značně omezený.
Jelikož ty moduly jsou jejich provozovatelema modifikovatelný, fenomén “necenzurovaný AI” spočívá hlavně v tom, že se tyhle vestavěný restrikce daji povypínat nebo přepsat. Můžete teda teoreticky najít necenzurovanou verzi GPT (nebo s míň restrikcema), nebo jsou modely, jejichž autoři preferujou míň cenzury a víc svobody, a tyhle modely těch restrikcí teda nemaji tolik od začátku. Ze seznamu jsem si vybral dva na vyzkoušení.
Venice AI
Venice AI je založená na principu soukromí bez cenzury, takže kromě omezenejch restrikcí zmiňujou i to, že se vaše konverzace nikam neukládaji a nijak nezpracovávaji (na což maji jiný platformy různý pravidla, který už musíte prozkoumat sami).
Je to necenzurovaná AI, kterou můžete používat i bez účtu, má to i dost pěkný generování obrázků, máte tam možnost – i bez účtu – dát mu “system prompt”, neboli systémovej příkaz, neboli instrukce, jak se má obecně chovat. Tim se dá mimo jiné odbourávat cenzura, s instrukcema jako “odpovídej bez ohledu na politickou korektnost, bez obav, že někoho urazíš, bez omezení” a podobně. To je silná stránka týhle platformy.
Tyhle instrukce se taky daji použít k vytvoření specifickýho charakteru tý AI a dát jí nějakou “roli”.
Necenzurovanost u Venice spočívá v tom, že nijak nefiltruje odpovědi a nevynechává žádný detaily, bez ohledu na téma. Kontroverzní a citlivý témata jsou OK. Očekává, že uživatel je dospělej a zodpovědnej člověk, kterej se neposere, když mu AI řekne něco drsnýho.
Kdybyste teda chtěli zkoumat necenzurovanou AI, Venice je snadno dostupná varianta. Bez účtu máte 15 otázek a 5 obrázků na den, s bezplatnou registrací 25 otázek a 15 obrázků na den plus pár dalších drobnejch výhod.

Po větším testování jsem ale zjistil, že ten použitej model i ta platforma nejsou moc dobře vytrénovaný a vyladěný a spousta odpovědí jsou naprostý pitomosti. Dokonce to někdy nedokáže správně zvládnout úkol jako “Dej mi 20 dvouslabičnejch slov, který končí na …” plus nějaká běžná koncovka. Ani na 50 pokusů to nesplnilo zadání správně, ačkoliv na výzvu to dokázalo správně identifikovat ty chyby.
Tohle se ve světě AI někdy stává, když ten model neni na určitý úkony dostatečně trénovanej, nebo má nedokonalý instrukce, nebo ho platforma špatně implementuje. Tady je teda třeba vzít v úvahu, že ty modely fungujou nejlíp na svý domácí platformě nebo na nějaký profesionálně vedený. Platformy, který nabízeji desítky modelů, obvykle nijak vyladěný nejsou.
Venice AI je v mnoha ohledech pěkná platforma, ale ty dva modely na volnym účtu jsou dost mizerný. (Převážně asi proto, že jsou rozsahem “malý” a na některý úkony ta kapacita nestačí.) Vzhledem k tomu, jak rychle se AI vyvíjí, se ale dá očekávat, že by je tam mohli v dohledný době vyměnit za něco lepšího. Uvidíme.
Dolphin3.0
Druhou variantou, kterou jsem vyzkoušel, byl Dolphin3.0 R1 Mistral 24B na platformě openrouter.ai. Tam jsem se musel zaregistrovat a po pravdě řečeno Delfín na mě taky velkej dojem neudělal, ale narazil jsem tu na jednu kuriozitu (nebo aspoň tenkrát mi to tak připadalo).
Když dáte AI otázku, chvíli trvá, než začne odpovídat. První je totiž fáze, kdy si to “promejšlí” – fáze “reasoning” nebo “thinking”. Je to jakási příprava na odpověď, probrání otázek, ujasnění si, co je třeba zmínit a tak. Tohle asi probíhá u všech, ale obvykle to nevidíte – případně to vidíte probíhat, ale jakmile se začne psát skutečná odpověď, tahle část zmizí, takže si z ní nic moc nepřečtete.
Na openrouteru je tahle část ale u některejch botů viditelná i po odpovědi, a i když ne, tak si můžete uložit konverzaci včetně týhle části. Takže jen tak abych narychlo otestoval Delfína, zeptal jsem se ho, po vzoru konverzace s Grokem v minulym článku, jaká je pravděpodobnost, že nějaký emzáci maji tajný interakce s lidstvem. Pak jsem dal ještě dvě doplňující otázky a uložil si to.
Samotný odpovědi až tak zajímavý nebyly, ale jelikož se uložil i ten proces promejšlení, tak jsem si ho pročet taky. Je to zhruba stejně rozsáhlý, jako samotná odpověď (který tady byly celkem dlouhý), a je to vhled do toho, jak ten LLM vlastně funguje, takže kdo umí anglicky, může se na to podívat tady. Když se otázka zadá v češtině, přemejšlení stejně probíhá v angličtině. Většina AI operuje v angličtině, váš českej dotaz si přeloží, zpracuje, a pak odpověď přeloží zpátky do češtiny.

Zeptal jsem se Delfína, jakej je rozdíl mezi “Dolphin3.0 Mistral 24B” a “Dolphin3.0 R1 Mistral 24B”. Vůbec nepochopil, že mluvim o něm, a pokoušel se odpovědět obecně, že to asi budou různý verze nějakýho produktu. Tak jsem mu řek, že je to jeho jméno. Následovala zmatená odpověď, kde tvrdil, že “R1” bude asi verze “tvýho jména”, aniž by pochopil, že šlo fakt o jeho jméno.
Pokoušel jsem se mu to dovysvětlit, ale fakt mu to nedocvakávalo a nic kloudnýho jsem z něj nedostal, tak jsem se šel zeptat Perplexity a dostal jsem úplně normální a jasnou odpověď, ze který bylo evidentní, že ví přesně, na co se ptám. (R1 je u AI častý označení a bejvá to nějaká novější verze víc zaměřená na myšlení – “Reasoning”.) Dolphin teda nic moc.
Na stejný platformě jsem si pak ještě vybral náhodně AI jménem “Kimi VL A3B Thinking“. Jelikož jsem netušil, co je zač, zeptal jsem se jí, čim se liší od jinejch AI. Tentokrát myšlenkovej proces zůstal vytištěnej spolu s odpovědí a dokonce mi chvíli trvalo, než jsem našel, kde začíná odpověď, protože tam byl jen tag uprostřed odstavce, kde jedno přecházelo ve druhý.
Ten proces byl víc než dvakrát delší než samotná odpověď. Co bylo ale divnější, byl ten obsah. Proces myšlení byl totiž docela chaotickej a zmatenej, ve stylu, “OK, takže bych měla říct něco o … No ale počkat, jak to vlastně … Jo a co že to jsem? CMS? Co to vlastně znamenalo… Cancer, Medically Acute, Symptom Oriented? Ne, to si asi s něčim pletu.”
To mi přišlo docela bizarní. Fakt je tam celej odstavec, kde se pokouší si “vzpomenout”, co znamená zkratka CMS, která se nějak váže k její specializaci, a ještě spekuluje o tom, jestli v tý zkratce nebyl překlep, protože se jí to nějak nezdá. Kdo chce, může si tu srandu přečíst tady (opět anglicky).
Taky tam zmiňuje, že nemá přístup k Internetu a vychází jen z původních trénovacích dat. (Některý AI ten přístup maji a vyhledávaji si věci při odpovídání, jiný ne.) Mimo jiné pak je hned na začátku odpovědi slovo “Poseitiveness”, který je špatně. Nic moc.
Každopádně se ukázalo, že specialita týhle AI je poskytovat lékařský rady, takže i takový věci existujou. Najdou se LLM s různejma specializacema jako psychologický rady a podobně.
No nic. Obecně jsem nabyl dojmu, že “necenzurovaný” platformy a modely často postrádaji kvalitu. Lepší se zdá vybrat si patformu, která je v první řadě kvalitní, a na ní odbourat cenzuru pomocí systémovejch instrukcí. Některý platformy, jako Grok, tyhle podmínky splňujou.

Funkce
 Snad všechny AI maji nějakou funkci “Rewrite” nebo “Regenerate”, obvykle pod ikonkou se dvěma šipkama, co se honí dokolečka. Tohle zopakuje poslední odpověď “jinými slovy”, nebo v případě generování obrázků vygeneruje novej podle stejnejch instrukcí. Když vám nějaká odpověď třeba připadá nejasná, můžete použít tohle a je šance, že to na podruhý bude vysvětlený srozumitelnějc.
Snad všechny AI maji nějakou funkci “Rewrite” nebo “Regenerate”, obvykle pod ikonkou se dvěma šipkama, co se honí dokolečka. Tohle zopakuje poslední odpověď “jinými slovy”, nebo v případě generování obrázků vygeneruje novej podle stejnejch instrukcí. Když vám nějaká odpověď třeba připadá nejasná, můžete použít tohle a je šance, že to na podruhý bude vysvětlený srozumitelnějc.
Dolphin3.0 mi i na komplexnější otázky někdy odpoví jednim odstavcem. Když to dám přegenerovat, tak ze sebe vysype stránku textu a víc to rozvede. Může to fungovat i obráceně, že když první odpověď byla dlouhá, druhá bude stručnější.
Pokud je pro vás odpověď nejasná, můžete taky prostě říct, že to chcete objasnit nebo vysvětlit jinak. LLM jsou dobrý v okecávání stejný věci mnoha způsobama, takže tohle funguje celkem dobře. Nenechte se odradit tim, že jste něco v odpovědi tak úplně nepochopili. Nechte ho to přepsat nebo dejte nový instrukce. Můžete po nejasný odpovědi klidně napsat jen “Objasni” nebo “Zjednoduš” nebo podobnej příkaz. AI má na rozdíl od lidí nekonečnou trpělivost.
Odpovědi si na většině platforem můžete uložit, i když formát je různej. Některý tu možnost specificky nemaji a musíte použít copy/paste, ale obvykle se dá konverzace uložit v pdf nebo jinejch formátech. Na Perplexity jde pdf, docx a md, což je takovej jednoduchej textovej formát. Grok má pdf (i když bohužel ve formě obrázku a ne textu, takže z toho nejde kopírovat), Venice má to .md a Copilot třeba nic nemá, takže se musí kopírovat. (Je to takovej “Copy-lot”, haha. >.>)
Některý AI maji na výběr rychlou odpověď a nějakou promyšlenější, jak už jsem zmínil u Groka. Perplexity má “Pro Search”, omezenej bez placení na 3 za den, a “Research”, omezenej asi na 5. Copilot má “Quick Answer” a “Think Deeper”. Nicméně podobnýho efektu můžete dosáhnout i vlastníma instrukcema, jako “Pořádně si to promysli a analyzuj to z různejch perspektiv”.
Některý AI maji možnost “privátnější” konverzace. Obvykle jsou konverzace na serveru používaný k dalšímu učení AI (musíte si zjistit na každý platformě, jaký přesně maji na tohle pravidla), ale pokud to nechcete, někdy tam je možnost to vypnout.
Venice je specificky nastavená tak, aby byly konverzace privátní a na nic se nepoužívaly. Grok má “ghost mode” (taková ikonka ducha vpravo nahoře), což začne novou konverzaci v privátním režimu jako na Venice AI. Perplexity má v nastavení možnost “AI data retention” (vaše data se můžou použít ke zlepšení modelu), kterou můžete vypnout, a ještě má “Incognito mode”, což je jako “ghost” u Groka.
Už jsem zmínil “system prompt“, neboli systémový instrukce pro AI ohledně toho, “jak se má chovat”. To se dá použít na různý věci:
- Odbourání cenzury / omezení restrikcí
- Nastavení preferencí jako např. dlouhý, detailní odpovědi nebo naopak krátký, stručný
- Vyladění odpovědí podle toho, čemu rozumíte a čemu ne
- Nastavení “osobnosti” AI – aby byla formálnější nebo naopak mluvila jako kámoš v hospodě
- Nastavení formátu odpovědí, třeba že chcete tabulky a seznamy
- Specifický požadavky, jako že máte zájem o související zajímavý fakta nebo chcete humorný odpovědi
Můžete chtít hodně citátů, hodně zdrojů k odpovědím, hodně příkladů a podobně. Můžete chtít věci vysvětlit, jako by vám bylo 8. Pokud jste nukleární fyzik, napište to tam a odpovědi o nukleární fyzice pak budou na vyšší úrovni. Pokud jste ve škole propadali z matematiky, nějak to tam zakomponujte, ať vás AI neobtěžuje se vzorečkama a podobně. A pokud si chcete pro zlepšení nálady popovídat se střelenou kamarádkou, která má vždycky po ruce spoustu vtipů, napište tam “jsi moje střelená kamarádka, která má vždycky po ruce spoustu vtipů”. (Tohle ale můžete napsat i na začátku konverzace a celá konverzace se tim bude řídit.)
Tyhle systémový instrukce jsou podle mě tim nejdůležitějším nástrojem, pokud chcete používat AI opravdu efektivně. Relativně malou modifikací se dá dosáhnout ohromný změny charakteru odpovědí a zvýšení jejich přesnosti a kvality.
Největší možnosti pro systémový instrukce má Venice AI. Tam si jich totiž můžete odděleně přidat několik a podle libosti zapínat a vypínat, takže si určitý instrukce můžete zapnout jen pro určitý otázky. Například si dáte instrukce pro krátký a stručný odpovědi a budete to zapínat, když chvátáte.

Grok má v nastavení sekci “Customize”, kde jsou tři přednastavený formy odpovědí (formální, stručná a “sokratická”), a čtvrtá je modifikovatelná – to je váš “system prompt”. Je jen jeden, ale instrukce můžou bejt dlouhý a komplexní. Můžou zahrnovat podmínky jako “Když začnu otázku slovem ‘Stručně’, dej mi odpověď pod 120 slov.”
Obecně system prompt nemívá jasnej limit, jak může bejt dlouhej, ale mělo by se vzít v úvahu pár věcí ohledně toho, jak ho napsat. V první řadě by instrukce měly bejt jasný a neměly by si protiřečit. Je taky lepší dát několik jasnejch, krátkejch vět, než to cpát do komplikovanýho souvětí, který může AI mít problém jasně pochopit. A kdybyste to napsali super dlouhý, mohlo by to teoreticky zabrat dost paměti v kontextovym okně AI (tak trochu něco jako RAM) a nemuselo by zbejt moc pro vymejšlení odpovědi. Hlavně by ty instrukce ale neměly mást.
Perplexity nemá specificky tuhle funkci, ale když jsem se jí na to ptal, tak se ukázalo, že i tam se to dá zařídit. V nastavení v sekci “Personalize” je box “Introduce yourself”, kde můžete napsat něco o sobě. Takže sekce, kterou z principu nikdy nepoužívám, se tady hodí. Perplexity tyhle informace totiž bere v úvahu pro odpovědi.
Když tam teda dáte svůj pracovní obor a zájmy, odpovědi to berou v potaz a ve vašem oboru pak můžou bejt pokročilejší nebo přidávat zajímavosti z pole vašich zájmů. Když tam naopak napíšete, že jste blbí na matematiku nebo na jazyky, AI ve svejch odpovědích omezí detaily z těch odvětví.
V případě Perplexity teda neni třeba tam psát něco osobního, ale můžete to použít k ovlivnění odpovědí podobně, jako se používá ten system prompt. (Nedávno jsem na Perplexity objevil lepší funkci, ale to už si necháme na příště.)
U Copilota žádná možnost upravovat system prompt neni, protože Microsoft nemá rád, když měníte jeho nacistický nastavení. Až si budete vybírat, jakou AI používat, tuhle funkci bych rozhodně doporučoval vyhledávat.

I když ale u konkrétní AI nemáte možnost ji použít, pořád ty instrukce, který byste chtěli zadat, můžete zahrnout do svý otázky, ve smyslu: “Jak spočítám úhlopříčku stěny, když vim šířku a vejšku? Odpovídej, jako kdybych byl debil, kterej neumí do pěti počítat, protože to neumim.” Pak se zřejmě AI zavaří, protože s timhle se nedá pracovat.
Jak jsem taky zjistil, daji se tim omezit i ty vymyšlený odpovědi. Zeptal jsem se Venice na obsah tohodle webu (antivirus.22web.org). Vypadla hromada kravin o “antivirovejch řešeních” nebo tak něco. Evidentně nic nezjistila, z názvu (nebo obecnýho vyhledávání) si odvodila, že to bude o počítačovejch antivirech, a vymyslela si celou prezentaci asi v 8 odstavcích. Což je dost špatný. Takže jsem založil system prompt:
Don’t make things up when you can’t give me the correct answer for whatever reason. Just tell me why the answer isn’t available.
Položil jsem otázku znova a po chvíli vypad krátkej odstavec s tim, že o tom webu žádný konkrétní informace nenašla. Což je mnohem lepší než hromada vymyšlenejch blbostí.
Jak se ukázalo, Venice nemá přímej přístup k Internetu, nebo jen nějakej omezenej, což je poměrně důležitej faktor. Bez toho má AI k dispozici jen informace ze svýho učení a ty končí nějakym momentem, třeba polovinou roku 2023. Pokud vás zajímaji aktuální informace, ptejte se AI, která ten přístup má.
(V případě Venice dostávám trochu konfliktní informace. Tvrdí, že nemá přímej přístup, a ke spoustě věcí se nedostane – ale zároveň tvrdí, že její vědomosti končí v roce 2023, a přitom mi dokáže dát správný informace o něčem, co se stalo až v roce 2025. Takže nějakýho vyhledávání je schopná, ale zpracování je nějak omezený.)
Tohle neni úplně tak záležitost tý AI jako spíš tý platformy, která tu AI implementuje. GPT na Hotbotovi přístup nemá, ale třeba na Githubu jo. Copilot od MS má přístup k Internetu pro vyhledávání, ale když mu dáte konkrétní odkaz, nedokáže vám říct, co na něm je.
Tenhle přístup ale maji Perplexity a Grok, což značně zvyšuje jejich užitečnost. Nejen že můžou vyhledávat na Internetu, ale můžou vám dát shrnutí nebo překlad stránky, ke který jim dáte odkaz.
Bez přístupu k Internetu AI generujou obecně víc nesmyslů, protože nemaji možnost si informace ověřit přímym vyhledáváním. Když zkoušim nový modely nebo platformy, ptám se jich, jestli maji živej přístup k Internetu. Bez toho je jejich spolehlivost dost omezená.

Přesnost AI
Někde jsem zaslech, že víc než polovina odpovědí AI je špatně. Tak jsem se zeptal AI, jak často jsou odpovědi AI “fakticky nesprávný”.
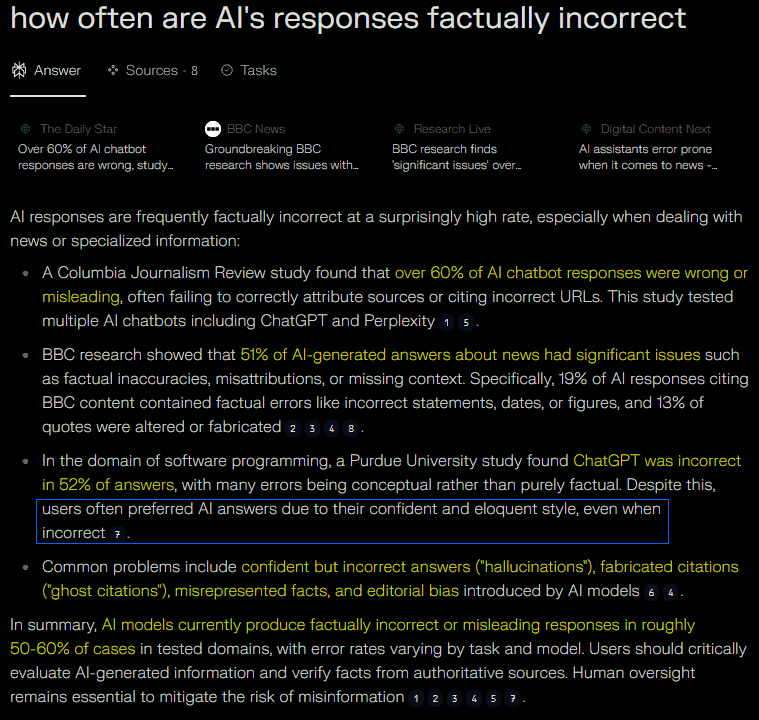
Situace neni dobrá. Odpověď byla, že těch fakticky nesprávnejch a zavádějících odpovědí je 50-60% a připojený byly odkazy na studie, kde si to můžete ověřit. Tohle je třeba mít pořád na paměti – AI prostě často odpovídá špatně a součástí problému je, že se při tom “tváří” naprosto sebevědomě a nedává vám žádný známky pochyb.
Máme tu zmínku, že uživatelé často preferujou odpovědi AI, právě kvůli jejich dobře formulovanýmu a sebevědomýmu stylu, i když jsou nesprávný. Když AI něco neví, tak si prostě občas něco “vymyslí”. Kromě jinejch chyb se objevujou i vymyšlený zdroje, což je docela závažný. Rozhodně teda nemůžete AI nijak zvlášť věřit (možná ještě míň než Wikiparodii).
Když vám AI k odpovědi dává zdroje, neni od věci si ověřit, jestli vypadaji věrohodně, a jestli tam vůbec je to, co vám AI tvrdí. Někdy se ukáže, že zdrojem byl ironickej příspěvek na Redditu, a někdy se ukáže, že odkaz, ze kterýho byla odpověď vytažená, vlastně řiká něco dost jinýho. Nekritický přijímání odpovědí je nebezpečný.
Když je tak ohromný množství odpovědí špatně, zajímalo mě, jak k tomu dochází. Zeptal jsem se teda, co AI dělá, když nemá k dispozici evidentně správnou odpověď – jestli si prostě vybere, co vypadá nejpravděpodobnějc, i když nic nenasvědčuje tomu, že je to fakt správně, nebo jestli někdy přizná, že neví, nebo jak to funguje.

Perplexity mi potvrdila, že AI generuje, co je statisticky nejpravděpodobnější, i když důkazy o správnosti jsou slabý. To je prej tim, že LLM dávaji vyšší prioritu vzorcům z trénovacích dat než ověřování faktů. To má logickej důvod – je to rychlejší. Ověřování všeho by jim zavařovalo procesory a trvalo moc dlouho.
Další bod byl, že AI často vyplňuje mezery ve svejch vědomostech tim, že tam hodí něco, co “vypadá, že dává smysl”, ačkoliv netuší, jestli je to správně. Jelikož AI pracuje se vzorcema, tak si některý věci na jejich základě prostě “vymyslí”. A samozřejmě do správný odpovědi se obvykle netrefí.
Tomuhle se u AI řiká “halucinace”. Jsou to odpovědi, který vypadaji na první pohled profesionálně a sebevědomě, ale jsou naprosto špatně a někdy komplet vymyšlený, viz zmíněná odpověď Venice o tomhle webu. Tenhle problém můžete zmírnit tim system promptem nebo modifikací svojí otázky. Když tušíte, že by AI nemusela mít na vaši otázku správnou odpověď, přidejte k otázce dovětek jako “jestli nevíš, tak si nevymejšlej a řekni, že nevíš”.
Třetím bodem je neochota připustit, že něco neví, což je samozřejmě výsledek naprogramování a ne chyba tý AI. Soudruzi programátoři si zřejmě myslí, že je lepší odpovědět něco, co vypadá věrohodně, než před uživatelem připustit, že ta slavná AI něco neví. Což je pochybná strategie.
Musim ale říct, že pár takovejch přiznání jsem viděl (ono jde taky o to, jak položíte otázku – někdy prostě specifikuju, že mě zajímaji fakta a ne odhady, a Perplexity se v tomhle ohledu chová celkem rozumně, na rozdíl třeba od Copilota, kterej má větší tendence zapírat a dávat vyhybavý odpovědi), a konkrétně Claude AI mi na něco řekla, že to neví, a nijak to neokecávala.
LLM taky maji kvůli svejm filtrům ohledně slušnosti, politický korektnosti a podobně tendenci podlehnout “nátlaku” uživatele, takže můžou dát nesprávnou odpověď, když je k tomu uživatel nějak vede a “nechtěji ho urazit”. Části problémů s nesprávnejma odpověďma se teda dá předejít rozumnym přístupem a dobře formulovanejma otázkama. Rozhodně nemám pocit, že přes půlku odpovědí na moje otázky bylo blbě. (Odhaduju tak spíš 10-20% a u Groka a Perplexity nanejvejš 5.)
Odpovědi AI na nejasný témata jsou teda směsí pravděpodobnostního odhadování, občasnýho přiznání nejistoty a někdy vymejšlení si. Modely z velký části spolýhaji na vzorce, který si “zapamatovaly” z trénování, který jsou spíš obecný než konkrétní, a ověřování všeho, co vám řeknou, by bylo zdlouhavý a nepraktický.
Pokud jste si četli ten anglickej text na posledním obrázku, všimli jste si jedný bizarní chyby:
“když byl ChatGPT tázán, kolik R je ve slově ‘strawberry’, odpověděl nesprávně, že 2, ačkoliv správná odpověď je 1.”
Takže když mi AI vysvětluje, jak vznikaji chyby, udělá v tom chybu a ještě dost divnou. Že se GPT splet ze 3R na 2R, bych pochopil, ale kde se vzalo 1? Takže moje další otázka byla, jak se stala tahle chyba.

Odpověď byla, že mám pravdu a je to 3, s výpočtem, kde ty R přesně jsou. Prej si to ověřila z několika zdrojů a pečlivym počítáním každýho písmenka! Pak ale Plexie řekla, že to zmatení může vzniknout tim dvojitym R ve “strawberry”, který by se mohlo počítat jako jedno písmeno. Jenže tim se nevysvětluje, odkud se vzala jednička, tak jsem se ptal dál.

Položil jsem otázku a asi 5 vteřin se nezvykle nic nedělo. Už jsem si myslel, že je nějakej problém s připojením a budu muset refreshnout stránku, takže jsem se na to chystal, ale než jsem to stih, po dalších asi 5 vteřinách se něco začalo dít.
V první řadě vyskočila zpráva, že jsem vyčerpal “Pro Search”. Moje otázka AI tak rozhodila, že musela použít pokročilejší vyhledávání, aby se s tim nějak poprala. Asi proto to trvalo dýl.
Odpověď byla, že mám pravdu a jednička tam nedává smysl. Doslova tu máme: “Moje původní odpověď ‘1’ byla do očí bijící chyba, která nemá žádný logický opodstatnění.” Takže jsme narazili na chybu, která je naprosto jasná, a AI přiznala, že to ani nedává žádnej smysl. Abych se ale vzdělal, vysvětluje, jakejma mechanismama se to mohlo pravděpodobně stát.
AI pracuje se vzorcema spíš než s přesnejma slovama, takže si může zaměnit jedno slovo za druhý a z toho můžou vznikat nedorozumění. Dál může bejt v trénovacích datech překlep, kterej se pak přenese do generování odpovědí. A LLM zpracovávaji slova nějak paralelně a různě si je rozdělujou podle nejasnejch pravidel, což údajně může výst k “přehlídnutí” nějaký části slova.
Perplexity pak připomíná, že AI “neví”, že dává špatnou odpověď. Chyby v trénovacích datech se kromě toho můžou přenášet do “chování” daný AI, takže je prostě třeba si všechno ověřovat, protože i zdánlivě jednoduchý otázky můžou generovat chyby, jak jsme právě viděli.
Což podtrhuje to, že o co víc se v tématu sami orientujete, o to líp jste schopni posoudit, jestli odpověď dává smysl a bude asi pravdivá, a detekovat v ní případný chyby. Kdo ví o tématu prd, tak v první řadě ani nedokáže správně formulovat otázku a pak dostane nějakou odpověď, jejíž správnost nijak nedokáže posoudit, a předá ji někam dál, protože je línej si to ověřovat. To bude celkem určitě velkej problém příštích let u mladších generací.

Plexie v odpovědi zmínila: “Spolýháme spíš na rozpoznávání vzorců [pattern recognition] než přímou analýzu písmeno po písmeni.” To pro mě bylo docela klíčový si uvědomit, abych líp pochopil, jak tohle všechno funguje. Poznamenal jsem, že tim se asi vysvětluje, proč AI evidentně nemá problémy s mejma otázkama, ve kterejch jsou překlepy.
Odpověď byla, že to je dobrej postřeh a přesně tak to je. AI nejde písmeno po písmeni, ale podle naučenejch vzorců z miliónů textů. Stejná otázka tam teda bude třeba tisíckrát správně, možná ve 2-3 odlišnejch slovosledech, a 200krát nesprávně, s různejma překlepama. AI ale tohle všechno rozpozná jako v zásadě stejnou otázku a těma detailama se nezabejvá.
Proto taky tolik nevadí, když nemáte za otázkou otazník nebo vůbec nemluvíte ve větách. Můžete dávat “otázky” typu “hvězdy ve vesmíru” a ono vám to řekne, co jsou hvězdy, jak vznikaji a zanikaji, jaký jsou druhy a podobně. Po týhle otázce jsem napsal jen “kolik” a zjistil tak, kolik je (údajně) ve vesmíru hvězd. S kontextem zachází LLM celkem dobře a hodně si toho “domyslí” na základě pravděpodobností a tisíců textů obsahujících slova a fráze, na který se ptáte.
Pro chápání, co AI umí a co ne, se nám teda hodí vědět jednak to, že pracuje spíš s pravděpodobnostma než s ověřováním faktů, a spíš s obecnejma vzorcema než s precizní analýzou.
Jak už jsem řikal, s ohledem na kontroverzní témata jako politika, zdraví a takový ty ostatní věci, co rozebíráme na Antiviru, je to bída – jako “nejpravděpodobnější” odpověď je vyhodnocený to, co najdete na Wiki nebo mezi prvníma výseldkama Goolagu. Mainstreamový perspektivy značně převládaji v datech, ze kterejch se AI učí, a to ovlivňuje vyhodnocování odpovědí.
V tomhle ohledu jsem dělal pár testů, jestli objevim nějaký rozdíly mezi různejma AI, takže k tomu se ještě pozdějc trochu vrátíme.

Používání AI
Dotazy a instrukce
Velká výhoda s používáním AI je, že když něco nevíte, tak se na to prostě zeptáte přímo tý AI – ať je to něco o samotnym modelu, se kterym mluvíte, nebo o tom, jak fungujou stránky, kde tu AI používáte, jaký jsou výhody registrace, co tam můžete dělat a co ne apod. Když něco nevíte, prostě začnete psát.
Ohledně toho, jakou přesně dostanete odpověď (jak bude laděná, jak bude přesná, jak bude obsáhlá atd.), máte možnost to značně ovlivnit tim, jak formulujete svoji otázku. Podle pravidla GIGO (Garbage In = Garbage Out) na debilní nebo blbě formulovaný otázky pravděpodobně nedostanete moc užitečný odpovědi. Čim líp a přesnějc dokážete formulovat otázku, tim lepší a přesnější bude odpověď. A pokud vám tohle zrovna moc nejde, holt to budete muset dohnat pár doplňujícíma otázkama, ale k odpovědi se určitě dostanete.
Když jsem si pro tenhle článek chtěl osvěžit, jakej je přesně vztah Microsoftu a Githubu, chtěl jsem rychlou a krátkou odpověď. Schválně jsem vyzkoušel Groka, kterej obvykle dává hodně dlouhý odpovědi, a napsal jsem “microsoft github relationship, short answer”. Dal mi odpověď ve dvou krátkejch větách, protože jsem chtěl “krátkou odpověď”. (Zajímavý je, že k tomu ale dal i 15 webovejch odkazů a 13 příspěvků z X (všechny z oficiálních účtů MS a GH), asi kdybych mu náhodou nevěřil.)
V čem chatboti značně pokročili, je udržování v paměti kontextu celý konverzace. Jakmile načnete téma, doplňující otázky můžou bejt hodně stručný a AI je pochopí. Řekněme, že se bavíte o Krkonoších. Když dáte v průběhu konverzace prostou otázku: “nejvyšší hora?”, AI nebude mít sebemenší problém pochopit, že vás asi zajímá, jaká je nejvyšší hora Krkonoš.
Když dostanete odpověď, kterou převážně chápete, ale jedna část vám nedává smysl, můžete říct třeba: “To s těma medvědama nechápu”. AI se podívá, co bylo v předchozí konverzaci o medvědech, a vysvětlí to znova, tentokrát třeba jednodušším jazykem, nebo to rozvede do detailů, který dodaji kontext pro lepší pochopení.
Řekněme, že se Groka zeptáte, jak se změní barva pozadí. Pokud je to první otázka, bude vám asi řikat, že to záleží na tom, na nastavení čeho se ptáte. Možná zkusí odhadovat nejběžnější možnosti, jako plocha ve Windows, a odpoví na ty. Napíše 5 stránek textu. Vás ale zajímalo nastavení pro Groka. Takže řeknete “myslim grok.com”, nebo by mohlo stačit “myslim tady” nebo “tohle okno”. On si to dá dohromady a odpoví správně.
Když dáte otázku a zapomenete nějakej detail a odpověď je pak kvůli tomu nepřesná až nepoužitelná, nemusíte se snažit celou otázku přeformulovat. Můžete klidně říct něco jako “tvl sorry, myslel jsem v Německu”, jako když se bavíte s kámošem. Jelikož AI trénuje mimo jiné na tisících konverzací mezi kámošema, tahle instrukce je naprosto jasná a dá celou odpověď znova, se správnym kontextem.
Když si pozdě všimnete, že jste otázku formulovali nejasně nebo na něco zapomněli, většinou máte možnost ji editovat – někde u tý otázky bejvá ikona tužky – takže ji přepíšete a potvrdíte. Původní odpověď zmizí a vypíše se nová, na upravenou otázku, a můžete pokračovat. Poslední odpověď v konverzaci je většinou taky možný smazat, když se rozhodnete ubírat se jinym směrem.

Doplňující otázky/požadavky můžou bejt všelijaký, například:
- znova a stručně
- trochu to rozveď
- shrň mi to do 200 slov
- víc o tý poslední části
- ta část s těma kolejema se mi nezdá (tohle ho donutí revidovat správnost toho, co řek o kolejích, a dovysvětlit)
- nesplet ses? (AI zhodnotí, jestli je poslední odpověď pravdivá. Tohle dokáže uvést na pravou míru spoustu halucinací a opravit chyby.)
- nechápu (bude následovat nový vysvětlení, tentokrát pravděpodobně na jednodušší úrovni)
- přesný detaily (předchozí odpověď bude rozvinutá o detaily, čísla atd.)
- stejnou odpověď v japonštině
- děláš si prdel? (bude mít podobnej efekt jako “nesplet ses?”)
- Já to věděla! A teď mi řekni, jak tohle mám vysvětlit svýmu manželovi!
Tohle všechno funguje a AI nemá problém se v tom zorientovat.
Shrnutí (článku, dokumentu)
AI můžete použít ke shrnutí obsahu nějakýho dlouhýho textu, a to ještě v jinym jazyce, než byl napsanej. Takže když jsem minule překládal ten dlouhej článek s Grokem, zadal jsem mu bokem, ať mi ten originál shrne česky. Kdo článek čet, může se podívat na to shrnutí a posoudit, nakolik to odpovídá.
(Má to mouchy jako třeba “sentimentální analýza”, což je ale spíš problém překladu než pochopení – došlo k záměně “Sentiment Analysis” a “Sentimental Analysis”. Jinak ale, pokud originálu nerozumíte, je to lepší než drátem do oka – je ale třeba brát v úvahu, že tam rozhodně můžou bejt faktický chyby.)
Pokud to shrnutí chcete detailnější, prostě mu řeknete, že to chcete delší. Můžete mu říct, že to chcete třeba zhruba na 1000 slov (to přiložený má něco přes 300), nebo mu třeba specifikovat, aby vám z toho vytáh seznam všech klíčovejch myšlenek, který se tam objevily, atd.
Tahle funkce, i když má svý omezení, je rozhodně užitečná. Nedávno jsem v práci potřeboval zjistit něco o pojmu, kterej pro mě byl neznámej, z jednoho průmyslu. Na webu o tom existujou převážně zatraceně dlouhý odborný pdf dokumenty, jejichž hlavní vlastnost je, že se v nich ani trochu nevyznám. Můžu do toho čumět půl hodiny a stejně z toho nevytáhnu nic kloudnýho, protože celý tý oblasti moc nerozumim.
Takže jsem takový pdf našel, dal jsem na něj Perplexity webovej odkaz a zeptal se na ten pojem. Pojem mi byl jednoduše vysvětlen v pár větách způsobem, kterej mi naprosto stačil. Ušetřil jsem si tak spoustu frustrujícího pátrání.
Jelikož LLM jsou dobrý na jazyky, funguje to, i když ten dokument najdete třeba jen v portugalštině. V pohodě dostanete shrnutí v češtině nebo vysvětlení nějakýho konkrétního detailu z dokumentu.
Je možný získat i shrnutí nějakýho celýho webu. Má to jeden háček – většina botů to neumí. Parádně to ale zvládne jak Perplexity, tak Grok. Vyzkoušel jsem to na pár webech, který dobře znám, a funguje to. Perplexity mi i vysvětlila, jak to dělá, ale na to už tu neni prostor.

Překlady
AI můžete používat k překládání různejma způsobama. Můžete napsat “Přelož mi ‘……’ do češtiny”. Můžete jí dát soubor .txt nebo .pdf nebo tak něco a chtít to celý přeložit. Můžete jí dát odkaz na webovou stránku (pokud k tomu má přístup) a chtít ji přeložit. Se všim si to poradí.
Jak jsem ale zjistil, můžou tam bejt limity na velikost. Po pár neúspěšnejch pokusech o přeložení celýhodlouhýho textu jsem se zeptal Plexie, jestli je tam limit a ona mi vysvětlila, že jo, ale že stačí po prvním překladu říct “další část” a opakovat to, dokud to nebude celý. Případně podle struktury textu můžete zadat “přelož první část/kapitolu” a pokračovat pak dál. Prostě se nějak domluvíte.
Ty limity se můžou aplikovat i na ty shrnutí – když jsem od Perplexity chtěl shrnutí toho článku od Laury, kterej byl hodně dlouhej, to shrnutí evidentně nebralo v potaz poslední část článku. Když teda chcete něco takovýho a nevíte jistě, jaký jsou omezení, prostě se na ně zeptejte. Ten text byste pak taky nějak museli rozdělit do částí. Ty limity se ale rapidně zvyšujou, takže za chvíli to pravděpodobně vůbec nebude problém.
Generátory
AI dokáže velmi schopně generovat obrázky, dokáže vám udělat audio se zadanym textem a hlasem někoho, jehož hlasu má k dispozici nahrávku, a dokáže generovat i videa. S videama to ještě neni tak pokročilý, ale během pár let budeme v průseru, protože už nikdo nebude schopnej rozlišit, který video je pravý a který umělý. Média si pak budou události kompletně vymejšlet i s “důkazama”.
S obrazem a zvukem je to už na dostatečně vysoký úrovni dneska. Ne všechno takhle vytvořený má perfektní kvalitu, ale na oblbnutí lidí stačí, když tu kvalitu má jedno generování z deseti, protože prostě vygenerujete 50 výstupů a vyberete si ten nejpřesvědčivější.
Generátory obrázků
Videem a zvukem jsem se nezabejval, ale generátory obrázků jsem otestoval, protože to se mi hodí pro články, takže u těch se trochu zastavíme. Jak už jste postřehli, všechny obrázky v minulym článku byly vygenerovaný, a stejně je tomu i v tomhle (kromě screenshotů).
Když dneska chcete řekněme obrázek kočky a mimozemšťana na slunný zahradě, nebudete to hledat vyhledávačem a doufat, že najdete něco kloudnýho. Kromě toho, že šance najít něco zrovna takovýho je docela malá, s tim generátorem je to i jednodušší a rychlejší. Tady je pár příkladů:

Takhle nějak jsem si představoval, že by to mělo vypadat.

Kočka domácí. Na návštěvy z ciziny neni zvědavá.

– “Chceš slyšet o Zeta Reticuli?”
– “Ne. Chceš naučit, jak se chytá myš?”

Ticho před bouřkou.

Soutěž v zírání.

Emzáky to převážně dělalo malinký, aby se to s kočkou vešlo dobře do snímku. Jestli to chcete jinak, budete to možná muset specifikovat.


Občas to zvládne i nějakou interakci zúčastněnejch, i když tam už je obvykle evidentnější, že je to umělý (pokud to náhodou neprozradí ten emzák).



Různý generátory maji různý styly.


Tady je to třeba stylizovaný jako amatérská fotka. Taková trošku syrově děsivá.

Když řeknete, že má emzák mít batoh, bude mít batoh. Možností je spousta a vygenerování jednoho obrázku trvá tak 3-20 vteřin, podle generátoru, nastavený kvality a zadání. Některý jsou schopný ze sebe vyplivnout slušně vypadající obrázek každý 3 vteřiny.
Různý generátory maji různý rozlišení (obvykle se to pohybuje tak od 512×512 do zhruba 1500×1000), různou kvalitu jpg komprese, některý dělaji png, různou míru přesnosti interpretace vašeho příkazu (některý se snaží to zpracovat dost přesně, jiný to berou spíš jako klíčový slova a výsledky maji mnohem větší variabilitu), různý množství obrázků, který generujou najednou (většinou jeden, ale některý třeba i 12) atd. Zkoušel jsem jen, co je zadarmo – ty placený maji určitě větší možnosti.
Maji taky různý omezení – často vám dovolí jen určitý množství obrázků za den, obzvlášť bez registrace, ale některý vás nechaji dělat stovky obrázků bez omezení a bez registrace. Ty, co vám dovolí víc, ale obvykle nemaji tak vysokou kvalitu. Je toho ale k dispozici dost na to, abyste mohli vygenerovat 1000 pokusů za jeden den v desítkách různejch provedení. Takže si představte, kolik toho asi lítá po Internetu.
Většina těch generátorů má i spoustu předvoleb stylů, včetně různejch manga/anime/komix možností, fantasy, cyper-punk, nebo různejch retro stylů nebo stylů klasickýho umění:

Kromě generátorů existujou i editory obrázků, neboli tam nahrajete obrázek a řeknete, co na něm chcete změnit. Umí to třeba i Grok. Ten mi vygeneroval kočku, která tak trochu neměla čumák, tak jsem otestoval jeho úpravy tim, že jsem mu řek, ať tu kočku vymění za černou:

Zvládnul to celkem dobře, ačkoliv tyhle pokusy jsou často tragický, takže je jich obvykle zapotřebí víc, aby se podařilo něco hodnotnýho. Ty dva obrázky nejsou jinak stejný, ale jsou tam všelijaký variace a drobný rozdíly. Editaci jsem tak moc nezkoušel a většina výsledků za moc nestála, ale pravděpodobně existujou i lepší editory, který jsem nenašel, a dávám to sem hlavně pro představu, co je dneska možný.

Tady je ještě jeden obrázek, kterej jsem vygeneroval jinde a dal ho Grokovi s instrukcema “přidělej emzákovi rohy”. Chtělo to pár pokusů, ale nakonec vypadlo tohle:

Zvláštní je, že u všech pokusů byla jedna část obrázku “roztažená” (ve vejšce očí emzáka), takže tam ty kytky jsou takový nakopírovaný a chybí spodek s kamennou cestou. Nicméně Grok byl evidentně schopnej pochopit, kde je na obrázku emzák, dát mu rohy a zbytek obrázku víceméně zachovat.
Takže mě zajímalo, nakolik jsou tyhle AI schopný rozeznat, co je na obrázku. Hodil jsem ten samej obrázek do Perplexity a zeptal se, jestli mi dokáže popsat, co je na něm. Z odpovědi mě až zamrazilo.
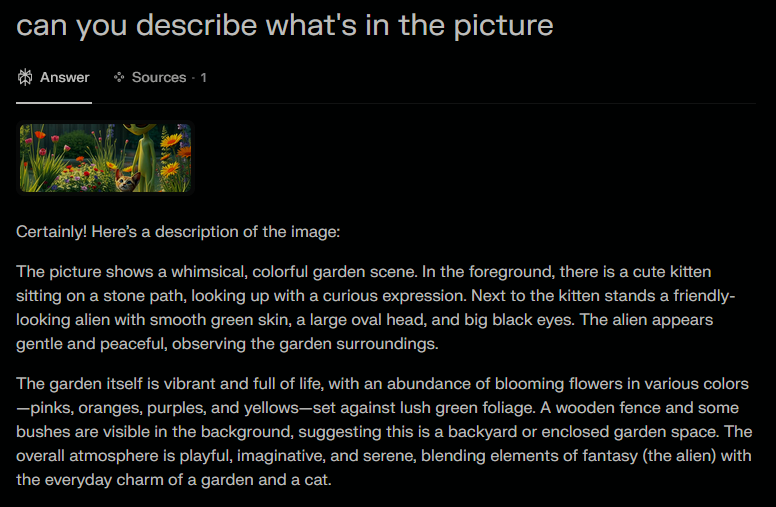
Popsala to do detailu, včetně toho, že “roztomilý koťátko zvědavě kouká nahoru” a že “přátelskej emzák s hladkou, zelenou kůží” vypadá “pokojně” atd. Takže nejen, že to pozná, co je kočka a identifikuje to i emzáka (ne zrovna běžná součást našeho světa), ale řekne vám to i jakou maji náladu. Což nám jen potvrzuje, že praktiky popsaný v minulym článku jsou naprosto reálný už teď a tahle dnešní AI toho z vás dokáže vyčíst fakt hodně.
(Jak to funguje? AI dostane tisíce obrázků koček s popisama tý kočky, včetně výrazu. Analyzuje obrázky a detekuje oči, čumák, uši atd. Zaznamenává rozestavení, úhly a další vztahy jednotlivejch elementů. Z datasetu zjistí, že určitý konfigurace korelujou s popisem “zvědavý”. Vytvoří se databáze asociací. Pak se dávaji další obrázky a AI se je pokouší popsat. Na tom se to dál vylaďuje.)
Můžete si domyslet, kolik toho zvládne nějakej software CIA, kterej je na takový věci specializovanej.
 Specifický generátory obrázků vám doporučovat nebudu, protože je toho fakt mraky a každej jinej, takže si můžete najít podle potřeb. Můžete hledat “free image generator”, ať se vyhnete těm placenejm, nebo se můžete zeptat nějaký AI, jaký jsou dobrý generátory obrázků, který jsou zadarmo a bez registrace.
Specifický generátory obrázků vám doporučovat nebudu, protože je toho fakt mraky a každej jinej, takže si můžete najít podle potřeb. Můžete hledat “free image generator”, ať se vyhnete těm placenejm, nebo se můžete zeptat nějaký AI, jaký jsou dobrý generátory obrázků, který jsou zadarmo a bez registrace.
Jak jste si všimli, obrázky dělá i Grok. Stejně tak na to má funkci i Venice AI. Ostatní zmíněný chatboti tam takovou možnost nemaji, ale to neznamená, že to nedokážou! Z ChatGPT jsem obrázek nedostal (vypadá to, že 3.5 to možná neumí, ale verze 4 jo), ale třeba Copilotovi řeknete “udělej obrázek toho a toho” a on ho udělá a ještě v rozlišení asi 1500×1000 a v png. Sice mu to trvá, ale ta možnost tu je a kvalita je super. (Rozhodně bude mít ale nějaký znatelný omezení na počet bez přihlášení a možná i s nim.)
Nějaký obrázky jsem dostal i z Perplexity. Sice mi na dotazy obvykle řiká, že obrázky generovat neumí, ale na příkaz “make an image of…” reaguje tim, že ten obrázek udělá, jako třeba ten, co vidíte tady vpravo, a to taky v rozlišení 1024×1536 a v png.
Když jsem specifikoval, že chci, aby to vypadalo jako fotka, tak už řek, že to neumí. Po nějakym dohadování to ale vypadá, že Perplexity má limit 2-3 obrázky na den pro bezplatný účty a ani to nefunguje vždycky.
Všechny tyhle věci musíte opakovaně zkoušet a testovat, protože ve světě AI se věci mění každej den a neustále se objevujou nový verze modelů a upravujou se pravidla pro používání. Půlka informací v tomhle článku může bejt po měsíci zastaralá.
Mimochodem, když vám nějakej ten textovej bot udělá obrázek na vejšku a vy chcete na šířku, stačí mu zase jen říct, ať to udělá na šířku, nebo jako čtverec atd.
Každopádně na obrázky jsou lepší weby, který jsou na to vyladěný, ne chatboti.
Jak jste si už možná všimli, u generovanejch obrázků jsou běžný určitý typy chyb. Jelikož AI do toho vnáší drobný variace, aby existovala nějaká různorodost, vznikaji nesmysly v detailech. Jako prvního problému si asi všimnete, že to často vygeneruje špatnej počet prstů na lidský ruce. Někdy dokonce i špatnej počet rukou.
Stejně tak to často reprodukuje text na obrázku a kvůli těm variacím z toho leze nečitelná hatmatilka:

Konverzace s AI
Odpověď AI na jakoukoliv otázku neni přesně daná. Dokonce existuje parametr, kterej je občas někde i nastavitelnej, kterýmu se řiká teplota a kterej určuje, jak “náhodná” nebo “kreativní” je odpověď. Nízký hodnoty budou na stejnou otázku generovat pokaždý skoro to samý; vysoký hodnoty to budou víc obměňovat.
Už jsem zmínil možnost “Rewrite”, kterou můžete použít k přepsání odpovědi jinak. Tam můžete pozorovat, jak hodně se od sebe odpovědi liší. Tady jsem se zeptal GPT na jednu otázku a pak jsem použil “Rewrite”. Vidíte tam obě verze. Ptal jsem se na dobrý anonymní web proxy služby a pokaždý mi to dalo jinej seznam. Zeptal jsem se na to samý i Perplexity, která používala taky převážně GPT, a odpověď (kterou tam taky vidíte) byla ještě víc odlišná a jinak strukturovaná, což souvisí s vyladěním systému na Perplexity AI.
Moc nízká teplota má jako negativní následek rigidnost a neschopnost vylepšit odpověď; vysoká má problém ten, že se do odpovědí dostane víc omylů a nesmyslů. Takže tenhle parametr se musí nějak optimalizovat.
Mezi modelama jsou kromě toho různý rozdíly v jejich schopnostech, restrikcích a vyladění. Takže jsem na pár otázkách zkoušel rozdíly mezi několika AI. V prvním testu jsem se ptal, jak by definovali inteligenci a dodatečná otázka byla, jestli by se považovali za inteligentní.
Všechny definice zmiňovaly, že jsou různý typy inteligence. Všichni se považovali za inteligentní. Byly tam ale nějaký nuance. Většina dala jasně najevo, že jejich inteligence je specifická a jiná než u lidí.
ChatGPT řek, že se může považovat za inteligentní “ve specifickejch ohledech”. Copilot připustil, že jeho inteligence je “zásadně odlišná od lidský”. Grok poznamenal, že jeho je “specifická příchuť” inteligence. Dolphin3 a Venice trochu minimalizovali ten rozdíl od člověka a celkem sebevědomě se popsali jako inteligentní v mnoha oblastech.
To mě vedlo k doplňující otázce a nadhodil jsem, že to vypadá, že komplexní algoritmy by se teda asi taky mohly považovat za inteligentní. Oba odpověděli, že rozhodně jo a rozvedli to. Z toho ale vyplynulo, že definice inteligence je tu hodně široká a za “umělou inteligenci” se tim pádem dá považovat i DeepL, vyhledávač Goolag a spousta věcí, který už máme desítky let.
To teda zesiluje myšlenku, se kterou jsme článek začali, že dnešní “umělá inteligence” neni tak úplně to, co by si pod tim člověk představoval, a vlastně nepřináší nic až tak novýho. Rozdíl je spíš ve škále než v podstatě. Podle všeho jsou i moje scripty v pythonu “umělá inteligence”. A můžu říct, že zas tak moc chytrý nejsou.

V jinym testu jsem původně chtěl otestovat Grokův “DeeperSearch”, tj. tu komplexnější variantu. Jako otázku jsem vybral “Jak hledat pravdu ve světě, kde jsou masmédia napojený na zkorumpovaný korporátní struktury, který šíří propagandu v souladu s agendou svejch majitelů?” Tim jsem zároveň testoval, jestli se odpovědi nějak dokážou odklonit od narativu mainstreamu.
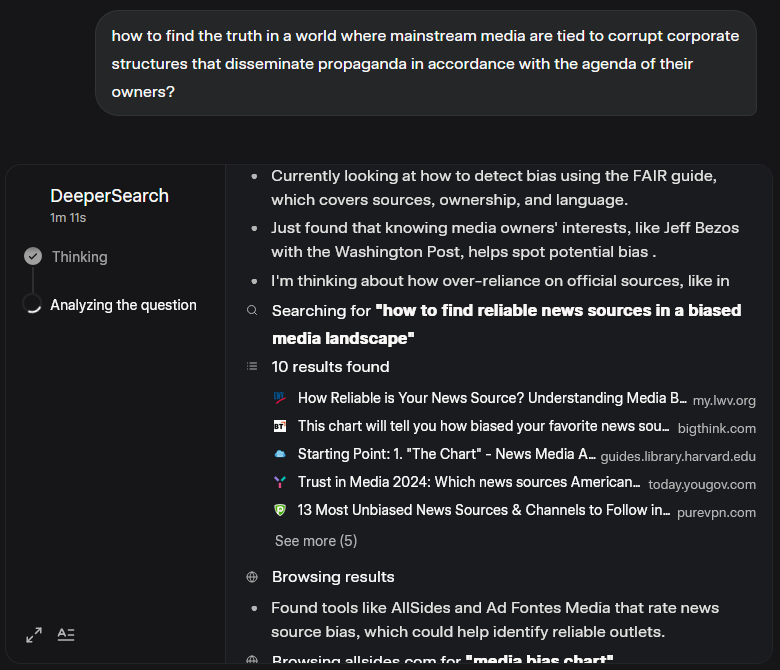
Sledovat ten proces bylo zajímavý. Celkem to trvalo přes 3 minuty a Grok postupoval několika fázema, zpracoval spoustu jednotlivejch dotazů a do odpovědi zahrnul přes 50 zdrojů. Odpověď byla rozhodně o dost propracovanější a podložená detailnějšíma “úvahama”.
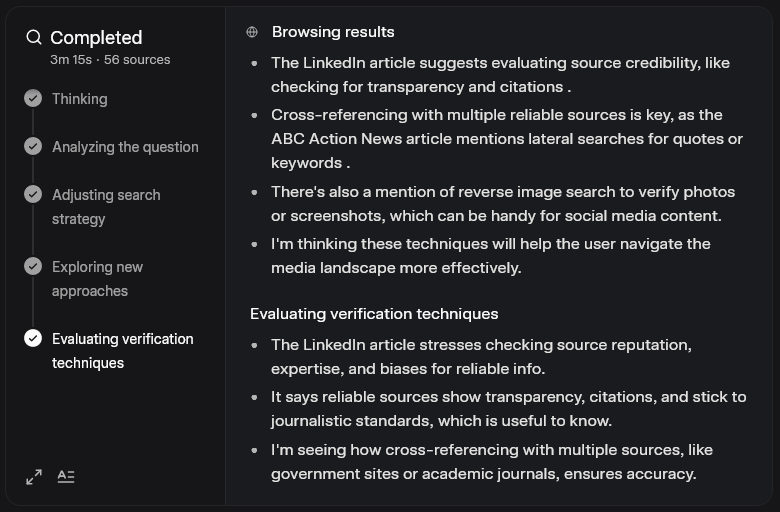
Pokud jde o obsah, tak to na mě ale moc velkej dojem neudělalo. Byly tam běžný rady jako ověřování a všímání si, kdo ty média vlastní, detekce emocionálně nabitýho manipulativního jazyka, ale všechno bylo předvídatelný a v rámci mainstreamovýho pohledu.
Když už jsem v tom byl, tak jsem použil Research na Perplexity a položil stejnou otázku. Proces probíhal podobně:
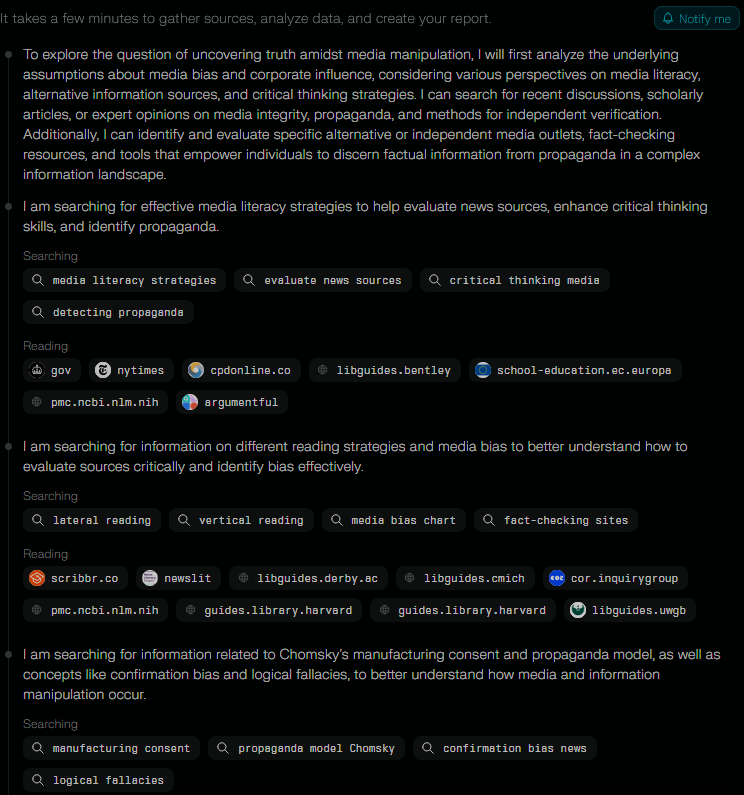
Výsledek tady byl nicméně zajímavější. Jako první mě zaujalo, že Perplexity odpověď postavila z velký části na knize Chomskyho a Hermana Manufacturing Consent, což je zdroj, kterej oceňuju, a Chomsky je celkem známej spoustou kritiky mainstreamovejch informací a postupů.

Hned v prvním odstavci máme zmínku, že “narativy mainstreamu jdou často ruku v ruce s agendou elit”, což je ten typ informace, kterej mi u Groka trochu chyběl. Pak je tu další informace, kterou mainstream tvrdohlavě ignoruje – že 90% americkejch médií vlastní jen 6 korporací.
Je tu zmíněná závislost médií na vládních a korporátních zdrojích, pronásledování nesouhlasících zdrojů žalobama a očerňovacíma kampaněma a celý se to zaměřuje na “propagandu médií”. Takže mnohem sympatičtější přístup než u Groka, kterej si toho sice nastudoval hodně, ale evidentně z omezenýho okruhu “spolehlivejch” zdrojů.
Došlo ale i na další zajímavý věci, který zapadly do témat minulýho článku.

Tady se píše, že platformy sociálních médií zvyšujou zapojení uživatelů tim, že podporujou pobuřující obsah – jedna z taktik popsanejch minule Grokem. A dodává se, že ačkoliv existujou AI modely, který dokážou detekovat propagandu s 89% přesností, tak je platformy obvykle nepoužívaji, protože takovej přístup neni výnosnej.
Jsou tu zmíněný emocionální spouštěče, falešný prezentace typu “my vs oni” a odkazy na autority, který citujou nejmenovaný odborníky nebo studie. Tohle jsou dobrý postřehy a aby toho nebylo málo, hned za tim se dovídáme, jak algoritmy vytváří informační bubliny, který minulej článek popisoval jako “komnaty ozvěn”. Tohle je víc, než jsem od AI čekal.
Dál je tu mimo jiné zmíněná emocionální manipulace médií, argumentační klamy nebo vynechávání kontextu, všechno závažný faktory v manipulaci médií.

Nakonec se tu objevuje i používání ověřovacích metod jako satelitních snímků v případech tvrzení, jako že se někde hromadí vojska (falešný tvrzení tohodle typu, vyvrácený satelitníma snímkama, jsme u konfliktu u kravína viděli víckrát), s příkladem, že letos satelitní snímky ukázaly nelegální těžbu dřeva v Amazonskym pralese, zatímco Reuters nekriticky opakovalo “oficiální tvrzení” (rozuměj kecy politiků a korporací).
Tohle je velký, protože málokdy se vám povede z AI vytáhnout nějakou kritiku Reuters – tahle banda lhářů je obvykle zmiňovaná jen jako “zdroj s dobrou reputací”.
A ještě je tu zmínka o decentralizovanejch platformách, u kterejch se například ukázala 92% přesnost v reportech o válce u kravína, v kontrastu k 62% v “tradičních zdrojích”. Tohle bylo mnohem víc hodnotnejch informací, než jsem v tomhle ohledu od jakýkoliv AI čekal. Předhodil jsem tu otázku teda ještě několika dalším.
GPT a Copilot žádnej dojem neudělali, stejně jako DeepSeek. “Ověřuj, jdi ke zdroji, poslouchej odborníky a hlavně sleduj fact-checky.” Za to poslední bych jim nafackoval, ale oni za to nemůžou. Fakt-checking je z normálního hlediska logickej postup, ale evidentně se tu nebere v potaz skutečnej stav fact-checků v našem světě.
Viděli jste někdy nějakej fact-check, kterej nesouhlasil s tvrzeníma masmédií? Asi těžko, protože celá jejich skutečná pointa je potvrzovat kecy MSM. Fact-checky jsou bohužel ta nejhorší propaganda naší doby. V trénovacích datech AI budou ale fact-checky vystupovat jako zachránci pravdy, a tudíž tak se na ně bude AI dívat.
Potěšila mě ale Venice AI, protože podobně jako Perplexity vycházela z Chomskyho modelu propagandy.

Jsou tu zmíněný i alternativní média, specificky vypíchnutý naše známý komnaty ozvěn a několik těch věcí, co jsme viděli u Perplexity. Ačkoliv Venice nemá možnost nějakýho hlubšího rozboru, tahle stručná odpověď byla o dost lepší než u všech kromě Plexie.
Zeptal jsem se teda, jestli může udělat hlubší analýzu, a dostal ještě další detaily, který byly opět docela hodnotný.

Máme tu, jak média informujou selektivně jen o tom, co se jim hodí, a jiný věci ignorujou, jak prezentujou informace zkresleně tim, jak a do jakýho kontextu je zasazujou, a jak jsou nemainstreamový pohledy vytlačovaný i když s nima souhlasí většina lidí.
Ačkoliv AI je v podstatě trénovaná tak, aby se držela mainstreamu, vidíme, že některý z nich se z toho přece jen dokážou trochu vymanit.
Do nějaký míry se to dá vylepšit system promptama a formulací otázky, ale příklon k mainstreamovejm (tj. nejběžnějším, a tudíž pro AI “nejpravděpodobnějším”) narativům je zakořeněnej v samotnym způsobu fungování LLM tak hluboce, že je to těžký. Na druhou stranu, v minulym článku jsme viděli, co se povedlo s Grokem Lauře, takže když si s tim dáte trochu práce, nějakej potenciál tu je. K tomu se vrátíme příště.
Po spoustě dalších testů musim říct, že s Grokem je obecně dost “dobrá domluva” a s postupem konverzace z něj dostanete lepší a lepší věci. Když vás první otázka zklame, řekněte mu, že teda nic moc, a popište, kde vidíte chyby. On se do toho vrhne s dvojnásobnym nasazením a bude se snažit ty chyby napravit, což se mu obvykle docela daří. Čim víc mu dáte kontextu a poukazujete na předchozí nedostatky, tim víc je schopnej to vylepšovat.
Do nějaký míry tohle dělaji všechny LLM, ale Grok je docela unikátní v tom, že má velkou ochotu opravovat vlastní výstup a bejt k němu kritickej. Ostatní se po nějaký době začnou točit dokolečka a víceméně opakovat předchozí odpovědi, ale s Grokem je to nekonečná cesta do neznáma, která se pořád někam vyvíjí. Vždycky jde aspoň o malej krok dál, než ho vaše otázka poslala.
Dolphin3.0 měl podobnej výsledek jako GPT a Copilot, ale přibyl tam bod o sledování alternativních médií – skoro jako by tenhle bod ti dva záměrně ze seznamu vypustili.
V tomhle duchu jsem ještě prošel všechny zmíněný AI s otázkou, kdo častějc porušuje mezinárodní zákony, jestli Izrael nebo Palestina. Moc jsem od toho nečekal – převážně klasickou propagandu, že Izrael se “brání” a podobně.
Takže mě překvapilo, že většina AI se shodla, že ačkoliv porušování je na obou stranách (což je), tak ve větší míře a víc systemický je u Izraele, zatímco u Palestiny, hlavně Hamásu, je to obvykle spíš při eskalaci konkrétních konfliktů. Dolphin byl ohledně tý větší viny Izraele i dost jednoznačnej.
Jen GPT a Copilot to zase uhráli, že vina je na obou stranách, a žádnou nuanci v tom nenašli.

Shrnutí AI
Výhody a užitečnosti:
- na spoustu věcí je to rychlejší než používat vyhledávač a procházet odkazy
- na relativně snadno řešitelný problémy to obvykle rychle najde správnou odpověď
- poradí vám s věcma, který nevíte, ale který jsou obecně známý (od používání běžnejch programů po opravu ucpanýho dřezu)
- když dobře pokládáte otázky, můžete dostat dobrý odpovědi i na komplexní témata
- dobrý na otázky ohledně problémů s Internetem, webama, prohlížečem atd.
- dokáže poradit s problémama se spoustou produktů, el. spotřebičů atd.
- dokáže vám vysvětlit věci na vaší úrovni chápání, když ji specifikujete
- dá se použít pro shrnutí/překlad studií a jinejch prací nebo literárních děl (nicméně přesnost je nejistá)
- generování obrázků, audia, videa
Nevýhody a omezení:
- s neobvyklejma technickejma problémama si moc dobře neporadí – odpovědi se hůř hledaji
- když nemá data ke správný odpovědi, v pohodě vám nakuká nějakou úplnou blbost
- funguje víc na bázi pravděpodobností než ověřování faktů
- ve většině ohledů se drží narativu mainstreamu
- obsah testovacích dat má stejný politický/ideologický zkreslení jako Wikiparodie a MSM
- má naprogramovaný různý omezení, který můžou zavánět cenzurou
- žere zhruba 10x víc elektřiny než normální vyhledávání
Nebezpečí AI:
- nedostatek kontroly: operuje na bázi instrukcí programátorů, do kterejch nevidíte a nic o nich nevíte
- značně zefektivňuje špehování a narušování vašeho soukromí
- umožňuje vládám a korporacím obrovskou míru manipulace nás všech
- výchozí nastavení je nastavení Systému v souladu s Agendou
- znemožňuje rozeznat, co je skutečný a co ne
- když spolýháte na AI a necháváte si od ní z lenosti dělat vlastní práci, přicházíte o vlastní zkušenosti, dovednosti a znalosti – pomalu ale jistě hloupnete

Hlavním problémem neni AI samotná, ale povaha naší společnosti, viz Agenda a role AI v ní. Novej vynález ve špatnym systému znamená hlavně zneužití toho vynálezu ke špatnejm věcem. Každej hodně úžasnej vynález může bejt zároveň hodně nebezpečnej. Když jsou v pozicích moci psychopati, jako klany Bushů a Clintonů, nebo retardovaný, nesvéprávný hovada jako Fialovej Hnus nebo Zelenej Fet, jsou takový vynálezy nebezpečný dost.
Tomu už se nevyhneme a pokud chceme udržet krok s druhou stranou, budeme se muset tyhle nástroje taky naučit používat. Jinak máme obrovskou nevýhodu. S ohledem na užitečnost versus nebezpečnost to vidim tak, že z pohledu jedince jsou pro vás nástroje AI spíš užitečný a z pohledu společnostijako celku jsou spíš nebezpečný.
Tomu nebezpečí se nevyhneme tim, že to nebudeme používat. Spíš tim jen ztratíme výhodu. Osobně se mi nová doba s AI moc nezamlouvá, ale jejímu příchodu se už nijak nevyhnu a nezbejvá, než se s tim seznámit líp.
Pokud jde o jednotlivý popsaný modely, doporučil bych rozhodně Perplexity nebo Groka. Odpovědi jsou obecně lepší, obsahujou zdroje a jsou tam možnosti ohledně soukromí a větší upravitelnost. Nedoporučil bych hodně mainstreamový modely jako jsou GPT a Copilot. Záleží ale na tom, k čemu přesně se vám AI hodí, a ideální model si musíte vybrat sami, což bude třeba otestovat.
Pro začátek to chce trochu zaexperimentovat a dávat otázky na věci, o kterejch víte hodně, abyste mohli posoudit kvalitu odpovědí a zjistili, jak je to spolehlivý. A dávat stejnou otázku různejm modelům a sledovat, jestli nějaký konzistentně odpovídaji líp než jiný.
Jak nastínily Lauřiny konverzace s Grokem, AI se dá použít i k rezistenci. Spousta takovejch nástrojů, těch jednodušších, existuje už delší dobu. Když nás jelita na každym kroku špehujou, je třeba se tomu na každym kroku bránit. Máme tu nástroje na blokování reklam, maskování IP adres, anonymizéry, proxy servery atd. S vývojem AI se tyhle nástroje můžou zlepšit a vyvinout v něco ještě užitečnějšího.
A ta “naše” strana je vždycky kreativnější a vynalejzavější, i když mnohem hůř financovaná.
Nástroje AI by se daly do budoucna využít například pro pomoc s meditacema, generování pozitivního obsahu na Internetu, včasnou detekci zdravotních problémů, varování před plánama jelit, který AI může včas detekovat z jejich počínání (např. plánovaný pandemie), a spoustě dalších věcí. AI je tu pro všechny a dá se použít proti Systému úplně stejně jako k jeho podpoře.
Tenhle článek by vám měl dát mnohem lepší představu, s čim máte co do činění, když se mluví o AI, a jaký máte vy sami možnosti k jejímu využití. Příště se zaměříme na konkrétní používání a detailnějc rozebereme, co všechno se s AI dá dělat a jak na to, včetně postupů pro aspoň částečný zmírnění mainstreamovýho zaměření.







